
基础知识学习
版权申明:本文为原创文章,转载请注明原文出处
基础知识学习
查漏补缺~
CNN
两大特点:(\(i\)) 大数据量\({-}\text{降维}\rightarrow\)小数据量(image) (\(ii\)) 有效保留图片特征
inspiration:模仿人类大脑,构造多层神经网络,较低层识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,在顶层做出分类
三部分:(\(i\)) 卷积(提取图像的局部特征) (\(ii\)) 池化(降维,防止过拟合) (\(iii\)) 全连接层(输出)
使用多个filter(卷积核)得到各区域的特征值,每个卷积核代表一种图像模式,用于提取图片一种局部特征
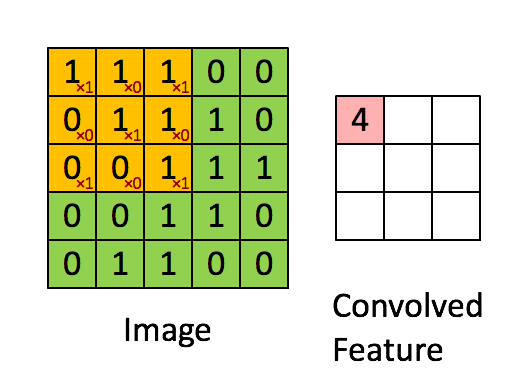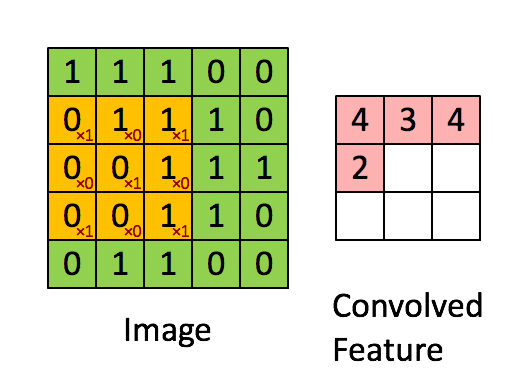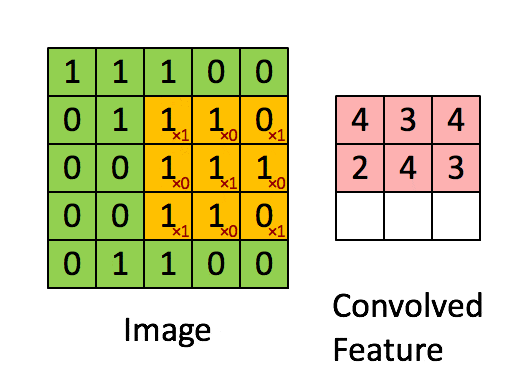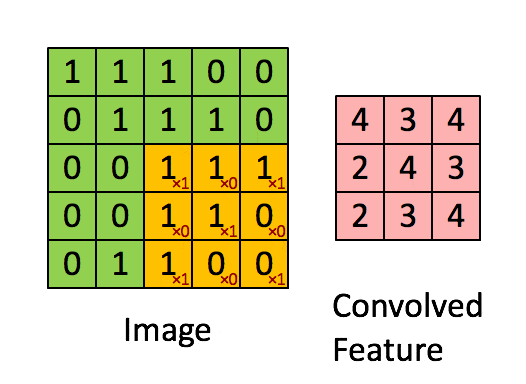
池化层即下采样,降低维度,因为卷积核较小,卷积之后图像仍然很大
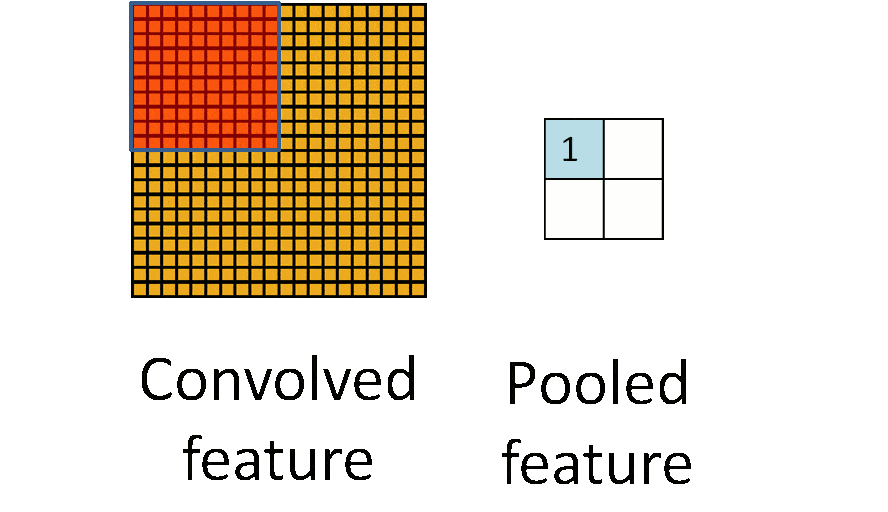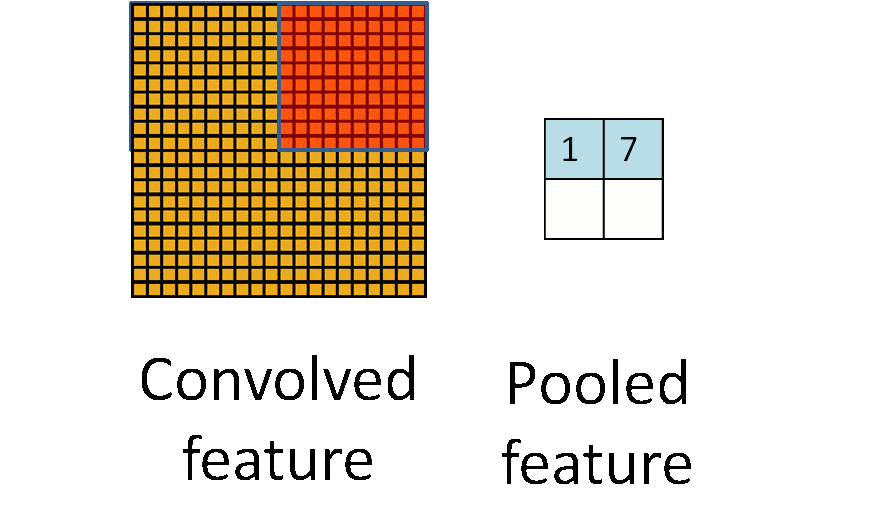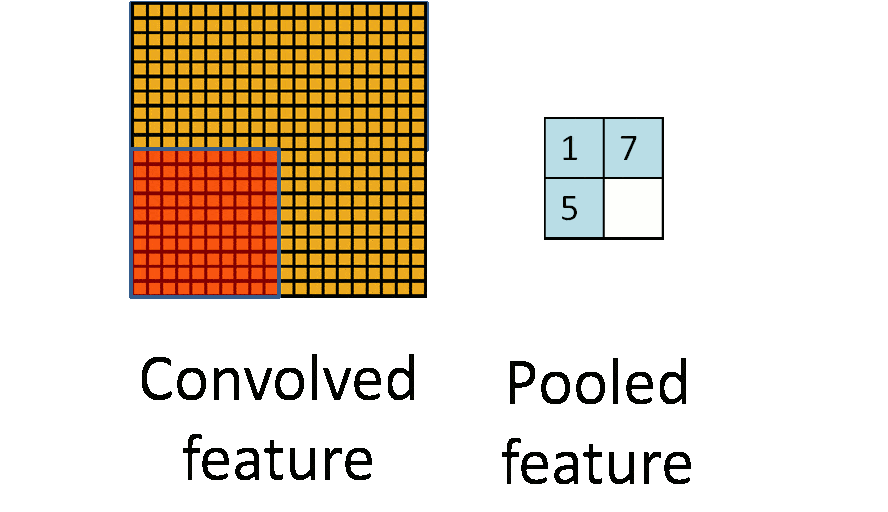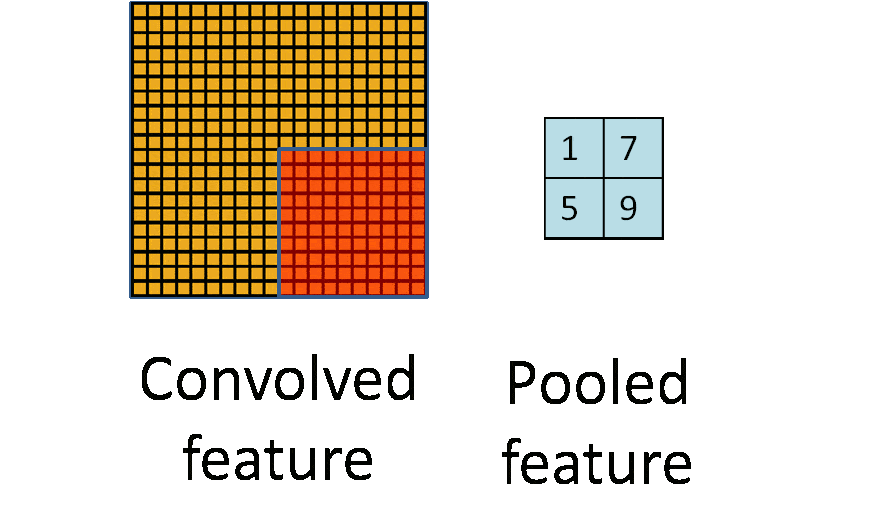
全连接层
归一化(Batch Normalization)
SGD(Stochastic Gradient Descent) : 随机梯度下降,即以一个样本的损失函数代替样本总的损失函数平均值对权值进行迭代
research target : 即使可以用SGD等方法提高效率,但是学习率,参数初始化dropout比例仍需自己设置和不断调整
正则化(Regularization):损失函数后面添加一个额外项,防止过拟合
- L1(Lasso):\(J+\alpha||w||_1\) 中 \(\alpha||w||_1\) 为L1正则项,指权值向量\(w\)中各个元素的绝对值之和,可以产生稀疏权值矩阵(大部分元素为0),可以用于特征选择
- L2(Ridge):\(J+\alpha||w||^2_2\) 中 \(\alpha||w||^2_2\) 为L2正则项,指权值向量\(w\)中各个元素的平方和,权重值会小,但是不会为0,防止模型过拟合
- dropout: 训练过程中以规定概率将部分权重置为0
issuse:训练前的归一化可以避免每次迭代遇到新样本都要学习新的分布,但前面层训练参数的更新将导致后面层输入数据分布的变化,因此BN是为了解决在训练过程中,中间层数据分布发生改变的情况
白化预处理方法:(\(i\)) 零中心化数据:每个特征减去均值 (\(ii\)) 数据去相关:将数据变换为一个新的坐标系,使得不同特征间的协方差为0,即特征之间互不相关 (\(iii\)) 重新缩放数据:每个特征的值除以其标准差,将每个特征的方差归一化为1
变换重构
训练阶段
- 归一化:\(\widehat{x}_i\leftarrow\frac{x_i-\mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2+\epsilon}}\)
- 重构:\(y^{(k)}=\gamma^{(k)}\widehat{x}^{(k)}+\beta^{(k)}\)
直接进行归一化\(\widehat{x}_i\leftarrow\frac{x_i-\mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2+\epsilon}}\)会破坏已经学习到的特征分布(将关键特征“推平”),故引入可学习的参数\(\gamma\)和\(\beta\)来恢复调整归一化后的输入,\(y^{(k)}=\gamma^{(k)}\widehat{x}^{(k)}+\beta^{(k)}\)中\(\gamma^{(k)}\)负责缩放(调整标准差),\(\beta^{(k)}\)负责平移(调整均值)
测试阶段
- 均值:\(\operatorname{E}[x]\leftarrow\operatorname{E}_{\mathcal{B}}[\mu_{\mathcal{B}}]\)
- 方差:\(\mathrm{Var}[x]\leftarrow\frac m{m-1}\operatorname{E}_{\mathcal{B}}[\sigma_{\mathcal{B}}^2]\)
- 前向传播:\(y=\gamma \cdot \frac{x - \operatorname{E}[x]}{\sqrt{\mathrm{Var}[x]+\epsilon}}+\beta\)
训练阶段归一化的均值来源mini-batch,测试阶段没有minibatch,单个样本难以反映整体分布,因此使用训练阶段每个mini-batch计算得到的均值求均值,用无偏估计修正方差均值
在CNN中的应用
将一整张特征图当作一个神经元,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的size。把每个特征图看成是一个特征处理(一个神经元),因此mini-batch size就是m*p*q,分别训练可学习参数:γ、β。相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。
Transformer
self-attention
eg: input(a1, b1, c1, d1) \(\rightarrow\) output(b1, b2, b3, b4),b1的产生如下(b1-b4可同时生成)
step1: 确定和a1相关的其他向量
通过计算a1和其他向量之间的 attention score \(\alpha\) (关联程度) 避免整个sequence都起作用,eg:\(\alpha_{1,2}=\boldsymbol{q}^{\mathbf{1}}(\boldsymbol{q}^{\mathbf{1}}=W^{q} \boldsymbol{a}^{\mathbf{1}}, \text{query}) \cdot \boldsymbol{k}^{\mathbf{2}}(\boldsymbol{k}^{\mathbf{2}}=W^{k} \boldsymbol{a}^{\mathbf{2}}, \text(key))\),接着进行softmax:\(\alpha_{1,i}^{\prime}=e x p\bigl(\alpha_{1,i}\bigr)\big/\sum_{j}e x p\bigl(\alpha_{1,j}\big)\)
step2: 用计算出的\(\alpha\) 当作权重,计算\(b^{1}=\sum_{i} (\alpha_{1,i}^{\prime} \cdot v^{i})\),其中 $v ^ { i } = W ^ { v } a ^ { i } $
待学习参数只有 \(W^{q}, W^{k},W^{v}\)
multi-head self-attention
multi-head指相关性的选择多样性,即得到q,k后再乘矩阵得到 \(q_{i, 1}, q_{i,2} ...\),\(k_{i, 1}, k_{i,2} ...\),最后得到\(b_{i, 1},b_{i,2}...\),再通过一个矩阵得到\(b_{i}\)
positional encoding
前面提到的attention机制并没有考虑位置信息,positional encodeing为每一个位置设置一个vector \(e_{i}\), i为位置,输入变为\(a_{i} + e_{i}\)
扩展
- Truncated self-attention(for speech):缩小attention计算范围
- vs cnn: cnn is a simplified self-attention,cnn考虑的特征是相邻的,由卷积核决定,self-attention考虑的特征是全局的,self-attention易于over-fitting,需要更多的训练资料
- vs rnn: 可替代rnn,rnn以当前状态和前一时间步隐藏状态为输入,rnn无法平行化所有输出,即使使用双向,需要保存最初始的输入才能对最后的输入起作用,self-sequence只要attention score符合,就直接考虑
- GNN(for graph): attention matrix可以只计算相连的node对
seq2seq Input is a sequence, output is a sequence(the output length is depended by model)
应用:语音识别文字/翻译/同声传译/聊天机器人 (都可以看做QA)
input sequence \(\rightarrow\) encoder \(\rightarrow\) decoder \(\rightarrow\) output sequence
install_url to use ShareThis. Please set it in _config.yml.

