
T2I
版权申明:本文为原创文章,转载请注明原文出处
T2I
Framework
类型
- Text -> 生成式AI -> video/image
- Image -> 生成式AI -> text
- Image -> 影像完善/风格转换/质量提升 -> new image 影像生影像
- Voice + image -> 生成式AI -> video talking head
基础要点
Image -> consisted of patches(像素点, eg:1024 * 1024) video -> consisted of frame(eg: frame per second -> FPS)
高精度图像要点:一些影像压缩技术
对于图片:
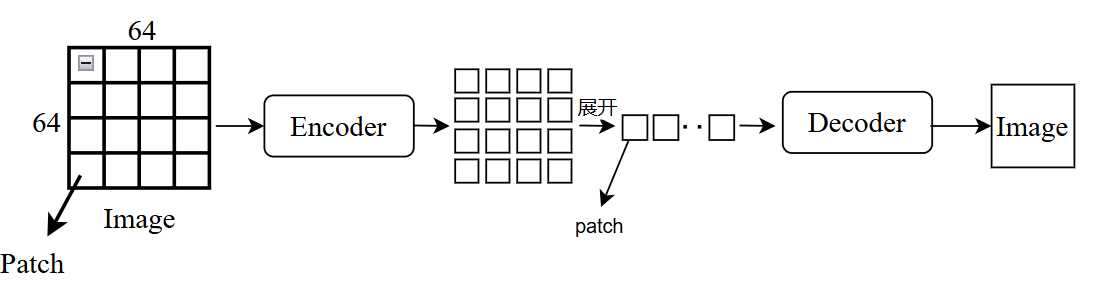
对于视频:

方法
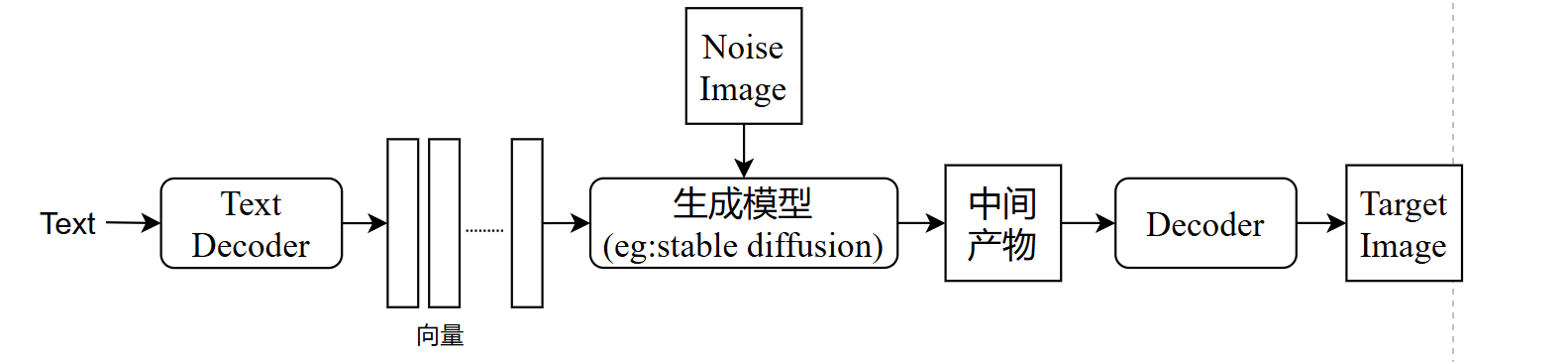
文字生图需要大量训练资料,有网站提供大量图片文字对,因此文字生图主要目标可理解为:
输入:文字 ----> 输出:patches
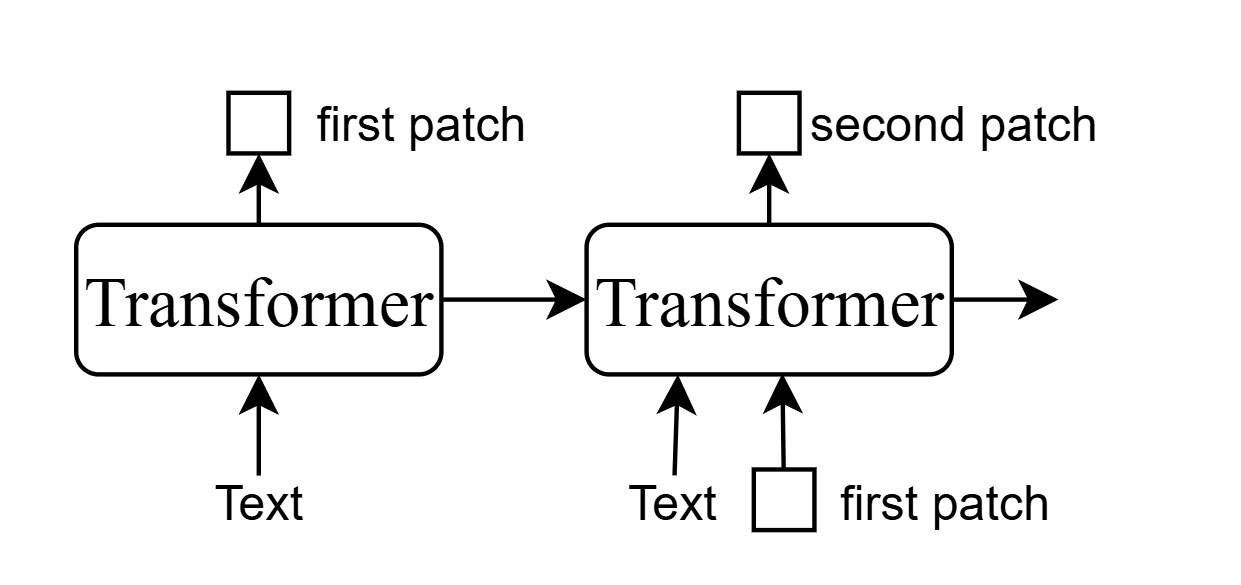
- One method is generating patch sequently(auto-regressive),很少用,patch之间不是依次传递作用:
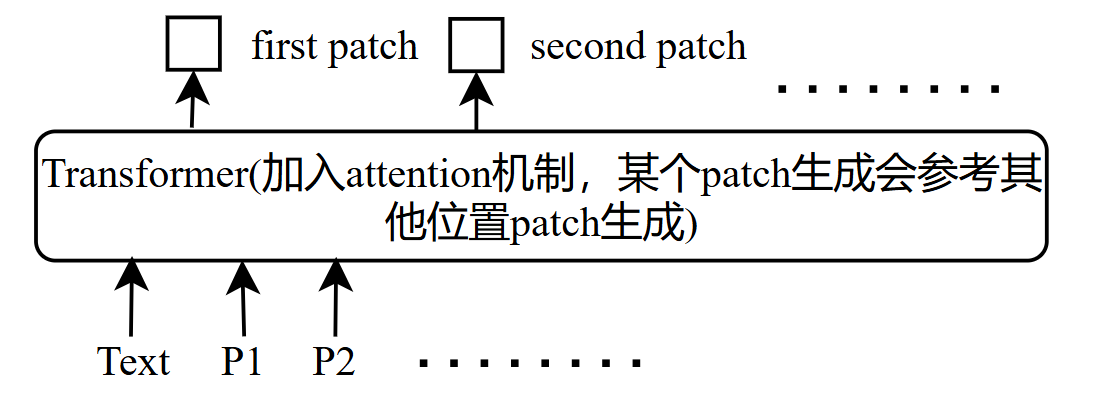
- 进化方式:同时生成patch,难以避免patch之间衔接不够,假如目标是生成一只小狗,这种方式可能导致各个patch的目标都是生成小狗,导致最终图像混乱,或者各个patch之间的杂序未统一,同一张图出现风格不同
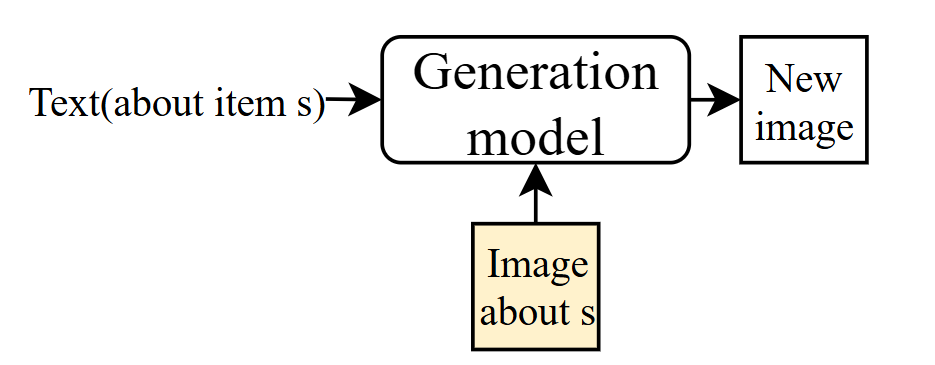
- 对于一些有独特特点的图片,比如一定要包含某个无法用语言完全描述的物品时,可使用个人化的图像生成,加入到图像生成中
- 文字生影片,方法和上面第二点相似,传入的即为P1.1
P1.2,生成的也还是patches,多个patches可组成一个frame
挑战:假设FPS为24,image为64*64,1分钟有1440个frame,600w个patch
每两个patch之间都相互考虑做attention,需要600w * 600w ->36兆次attention
Temporal attention:不同frame中相同位置的patch才做attention -> 1440^2 * (64*64) -> 85亿次attention
Spatial attention:同一个frame中所有的patch才做attention -> (6464)^2 1440 ->240亿次attention
衡量方式
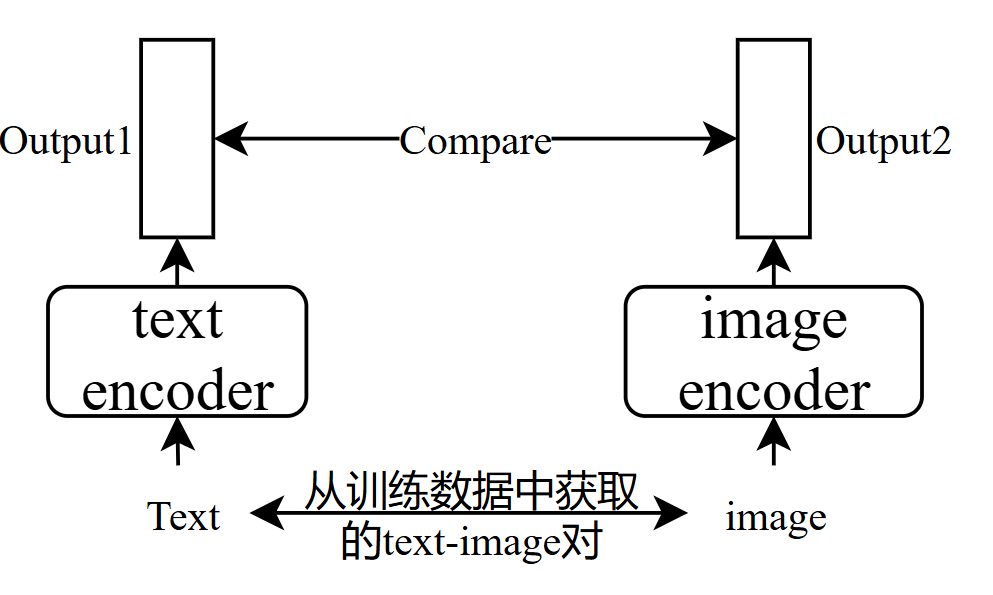
- clip score:contrastive language-Image pre-training:有400million的text-image对,方法如下,正确配对->高分,错误配对 -> 低分,正确样本为官方数据,负样本为随机打乱text-image对
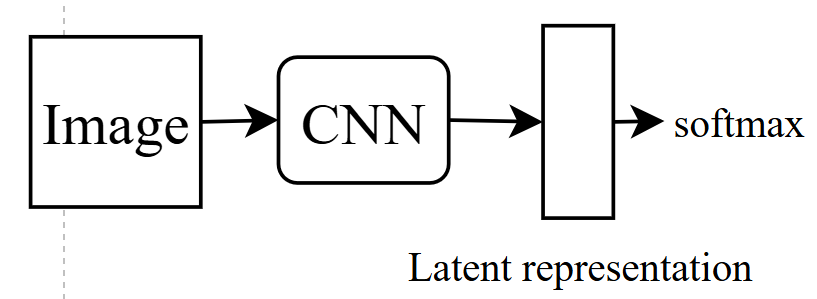
- FID: 先有一个pretrain好的cnn model,用于影像分类,将真实的latent representation和生成图片的latent representation进行比较(需要大量样本)
经典方法
Variational Auto-Encoder(VAE)
- 挑战:一张image由多个patch组成,patch之间虽然能用attention相互影响,无法避免patch之间风格不一致,无法统一(因为model本身就需要联想)
- 解决方案:添加标注,即资讯
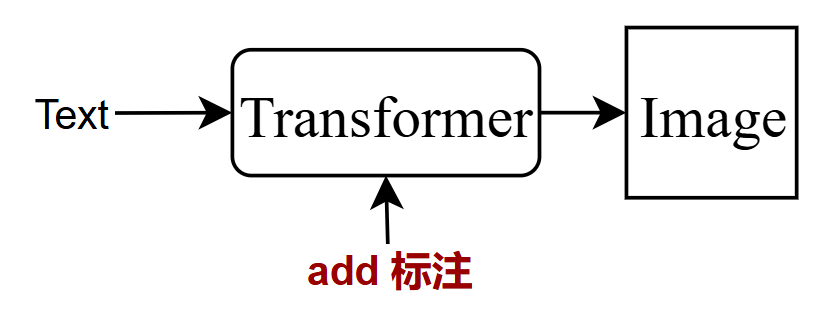
模型训练(将资讯抽取和图像生成一起进行训练优化,先根据图像生成资讯/标注,再根据标注生成图像,尽量使得生成的image和原始的image足够相似),该过程称之为auto-encoder
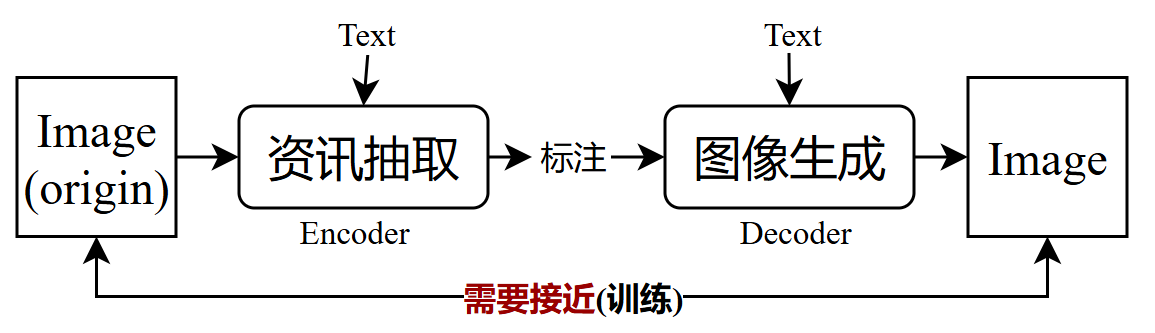
图像生成时标注是随机生成并加入到图像生成的模型中,最终生成图片,因为抽取的标注一般不为文字,而是向量,不同位置数字代表不同信息,因此真实生成图片是标注可随机产生,即随机确定风格
- 进阶使用
- 在通过encoder获取到的标注可以自行增减向量,比如原始图片为笑脸,可在生成的标注中减去笑脸向量,加上臭脸向量,在生成图片,最终生成的图片即为臭脸
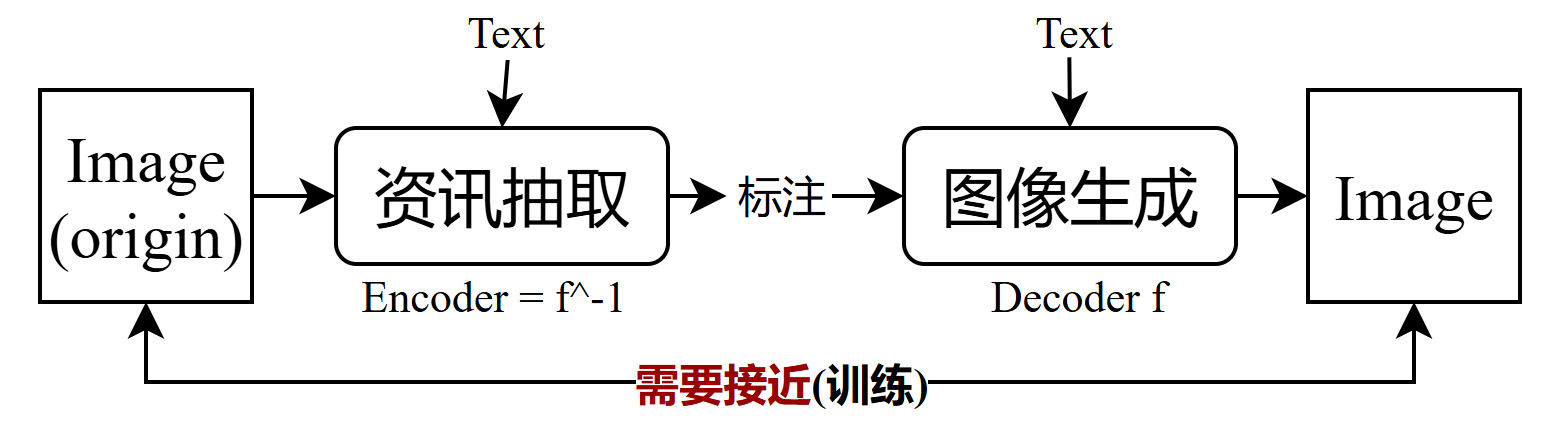
Flow-based
- 要点:和VAE类似,不同之处在于,Flow将资讯抽取当作图像生成的反过程,即VAE中的Encoder为Decoder^-1,这就要求Decoder
f函数要有反函数
Diffusion
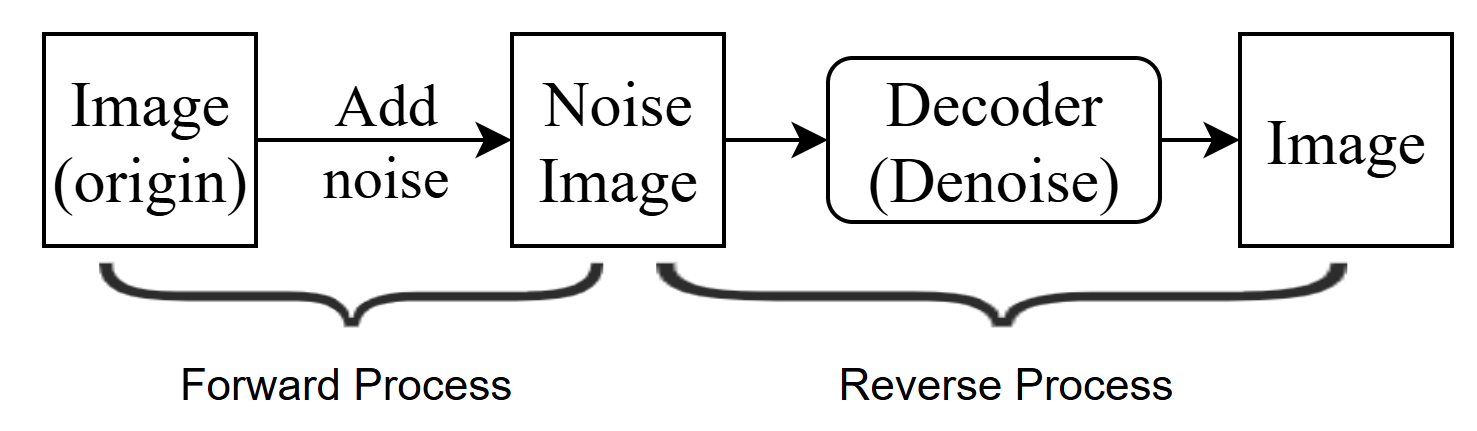
- 模型框架(分为forward和reverse两部分)
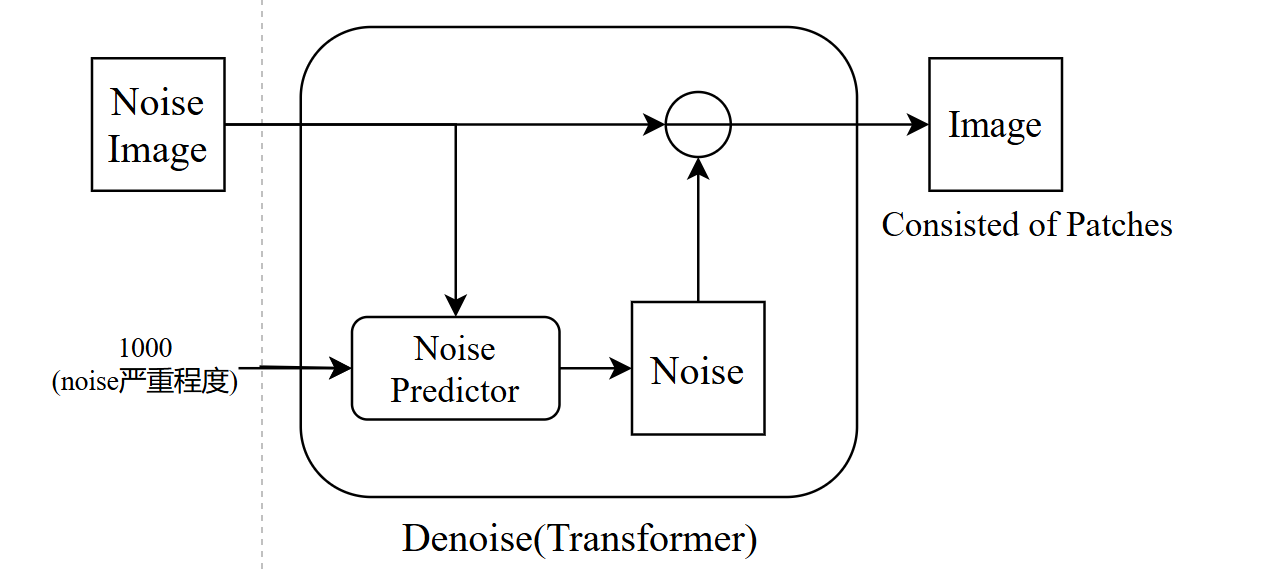
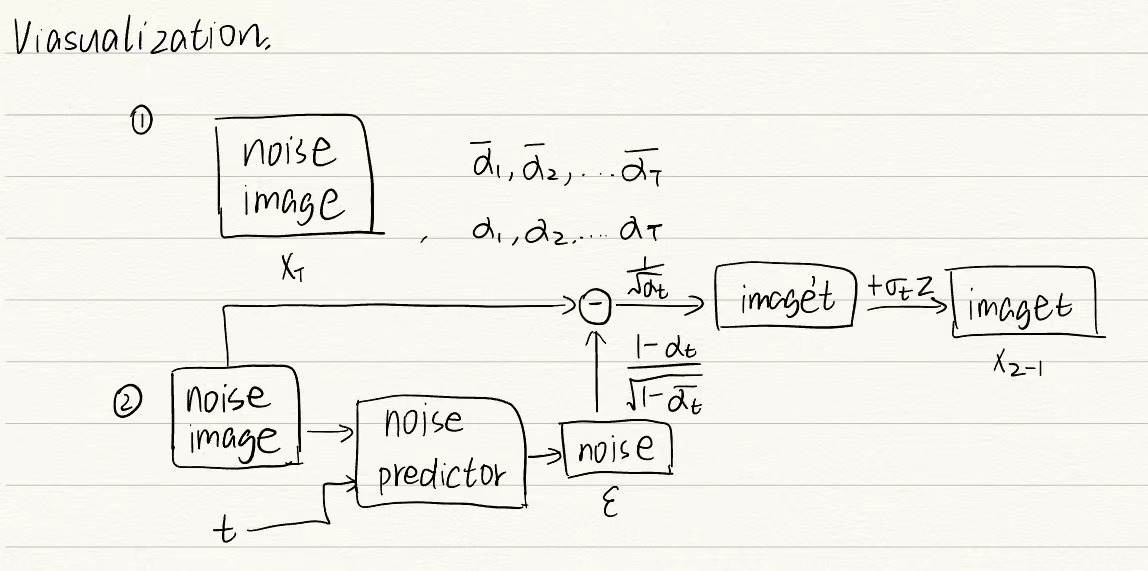
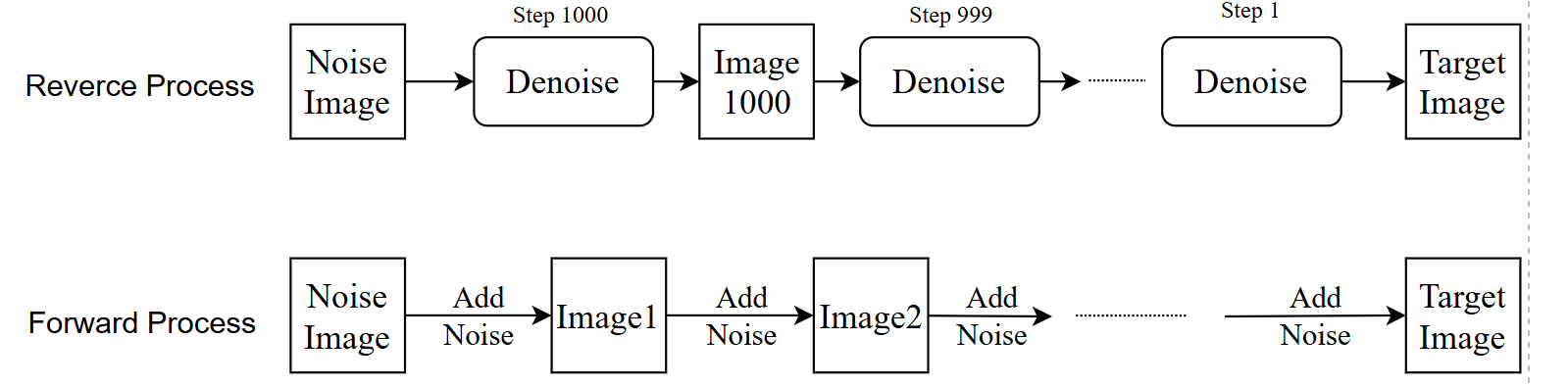
- Reverse Process:Noise image为随机生成的和target
image尺寸一致的噪声图片,step后面的数字是和Forward过程相对应的,该图相当于做了1000次的Denoise,目的是一步步过滤掉noise
image中的噪声

Denoise细节:由于每一步传入的image噪声程度不同,即随着不断地Denoise,图片的噪声会不断减少,因此添加新的输入用于表示noise严重程度
另外Denoise的方法是先为输入的noise image生成一个纯noise,再将输入的noise image减去预测出的noise,最终得到该步的输出
- Forward Process(diffusion model):即Noise
predictor训练过程,首先将一张干净的图不断的加噪声,最终生成一张noise
image
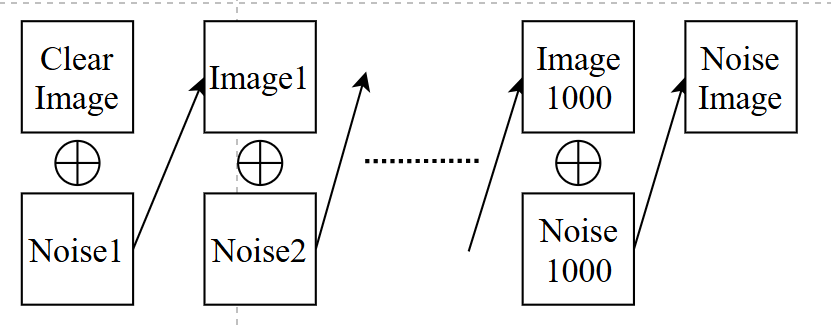
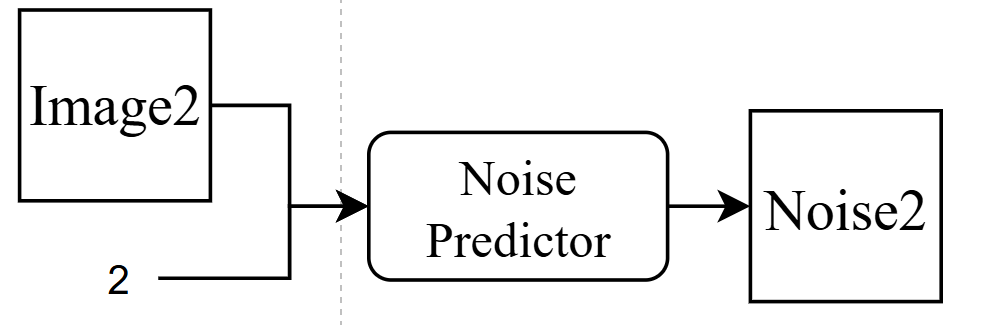
然后将数据用于noise predictor训练,这里的2是noise程度,即image2-noise2 = image1,达到上面的reverse效果
- 结合text:即denoise增加输入text,相应的forward过程也要加入text
- 完整框架
- 训练
noise predictor过程(forward)
reverse过程



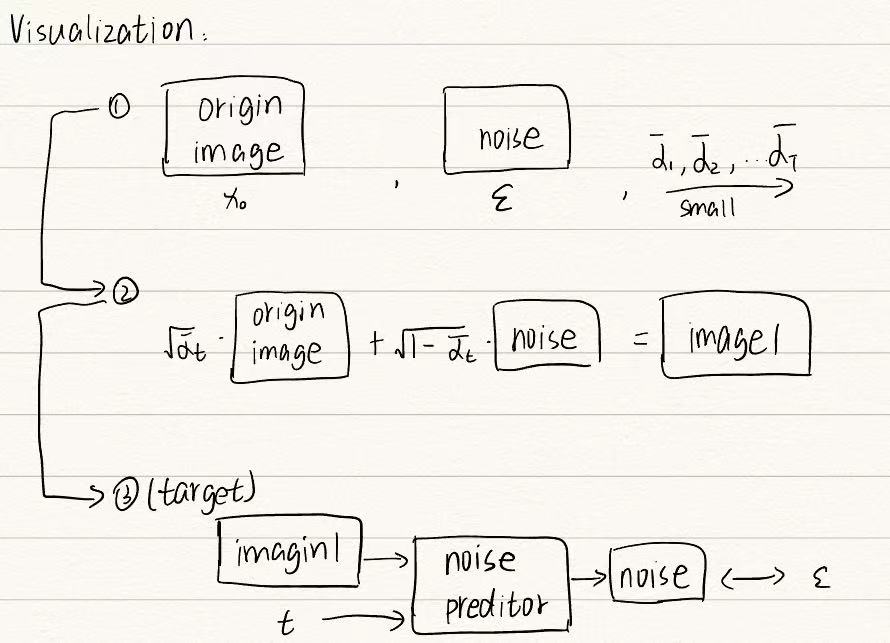
实际上的noise是一次性直接生成的,而不是逐步添加杂序
- 代码细节:
怎么衡量output image和真实image之间的接近度->最大似然估计,即输出图片为预期图片的概率的乘积最大的网络参数

首先看VAE过程,目标是最小化输出G(z)和目标x之间的差距,然后找logP(x)的下界

类似的DDPM过程,确定logP(x)的下界
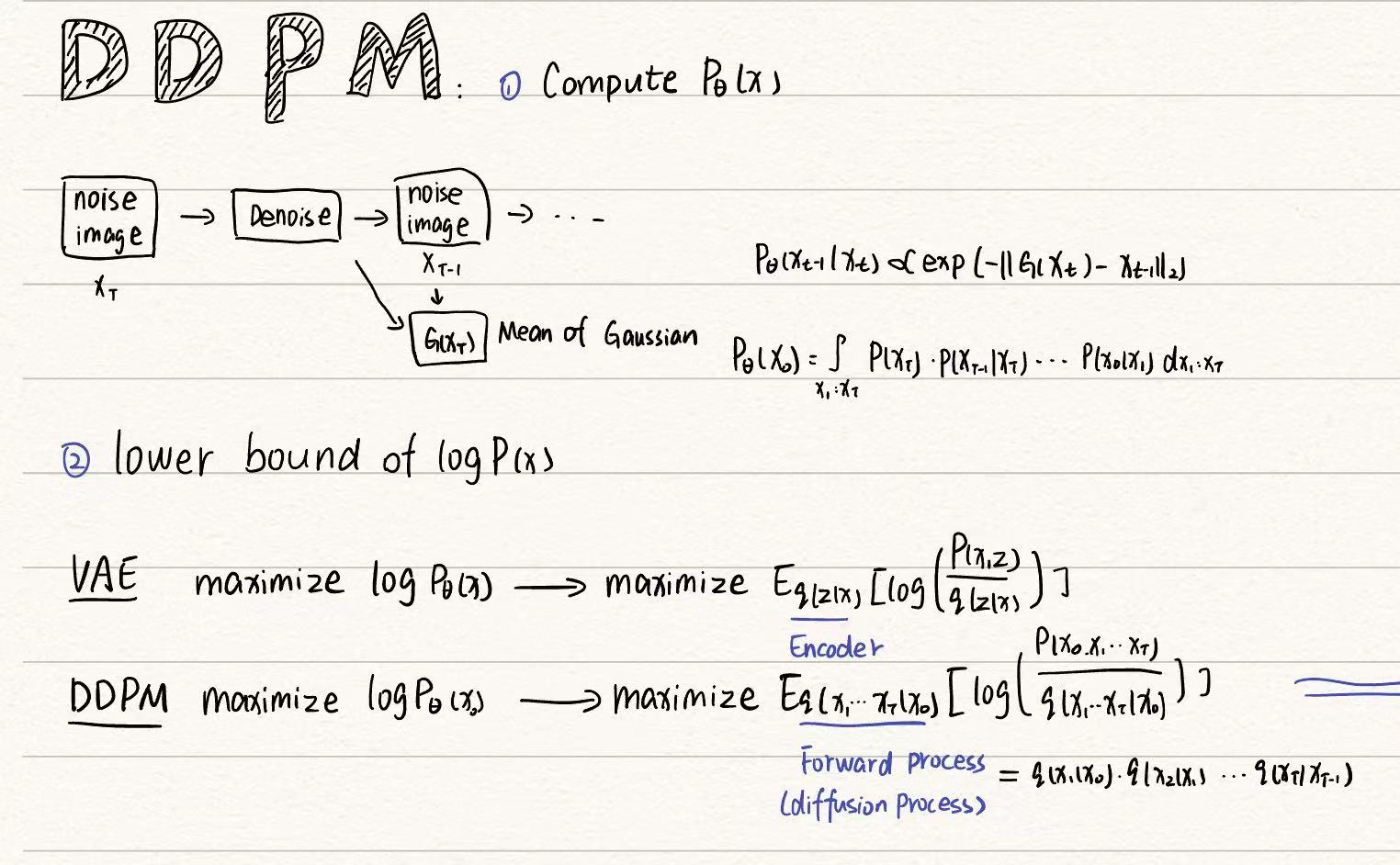
计算过程

GAN(可作为一种外挂,即VAE+GAN, Flow+GAN, Diffusion+GAN)
和其他模型有本质区别(Discriminator来衡量生成图像的好坏,类似于clip)
训练方式:搜集大量的image-text pair作为正样本,准备一个不好的文生图模型,将text和生成的image配对作为负样本

install_url to use ShareThis. Please set it in _config.yml.

