深度学习week5_1
版权申明:本文为原创文章,转载请注明原文出处
深度学习week5_1
为什么选择序列模型
序列模型的适用范围
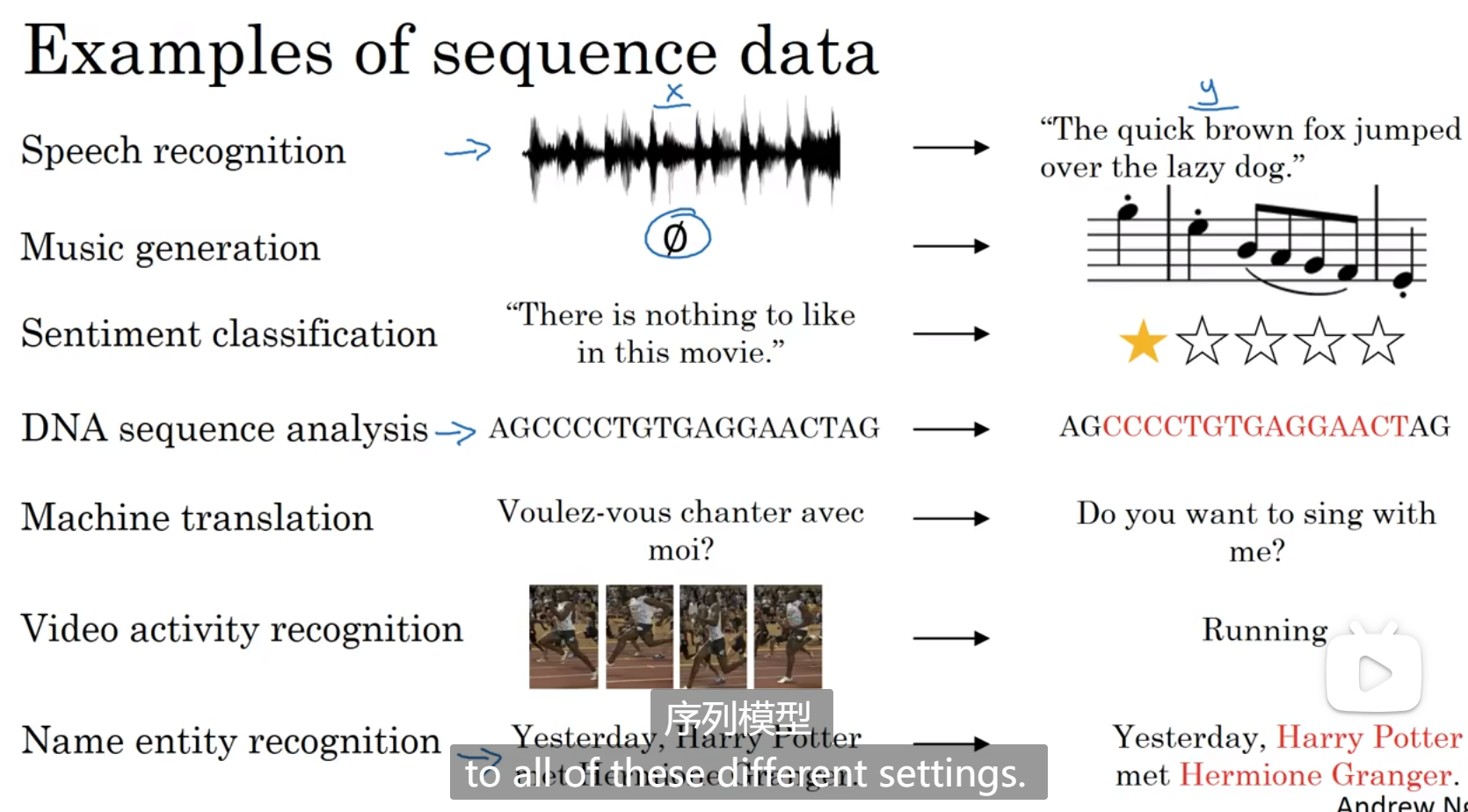
数学符号
X(i)< t >表示第i个样本的第t个单词,T(i)表示第i个样本的单词总数
y(i)< t >表示第i个样本的第t个单词的判断结果,1或者0


有一个词表存储了所有的单词,x就用one-hot的方式表达,one-hot的意思是,一个列表中只有一个值为1,表示该词在词表的某位置,如果遇到了不在词表中的单词,就用
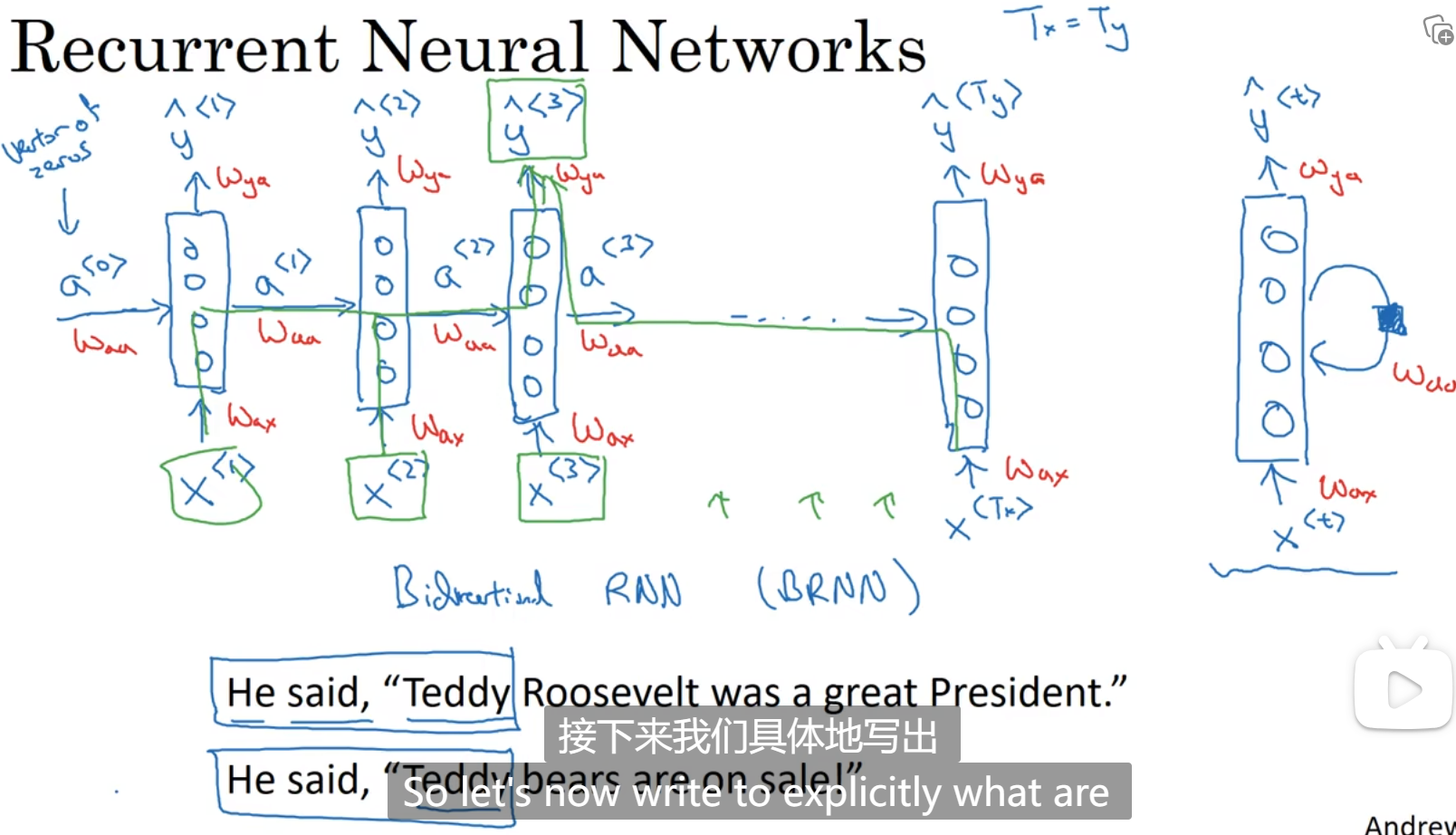
循环神经网络
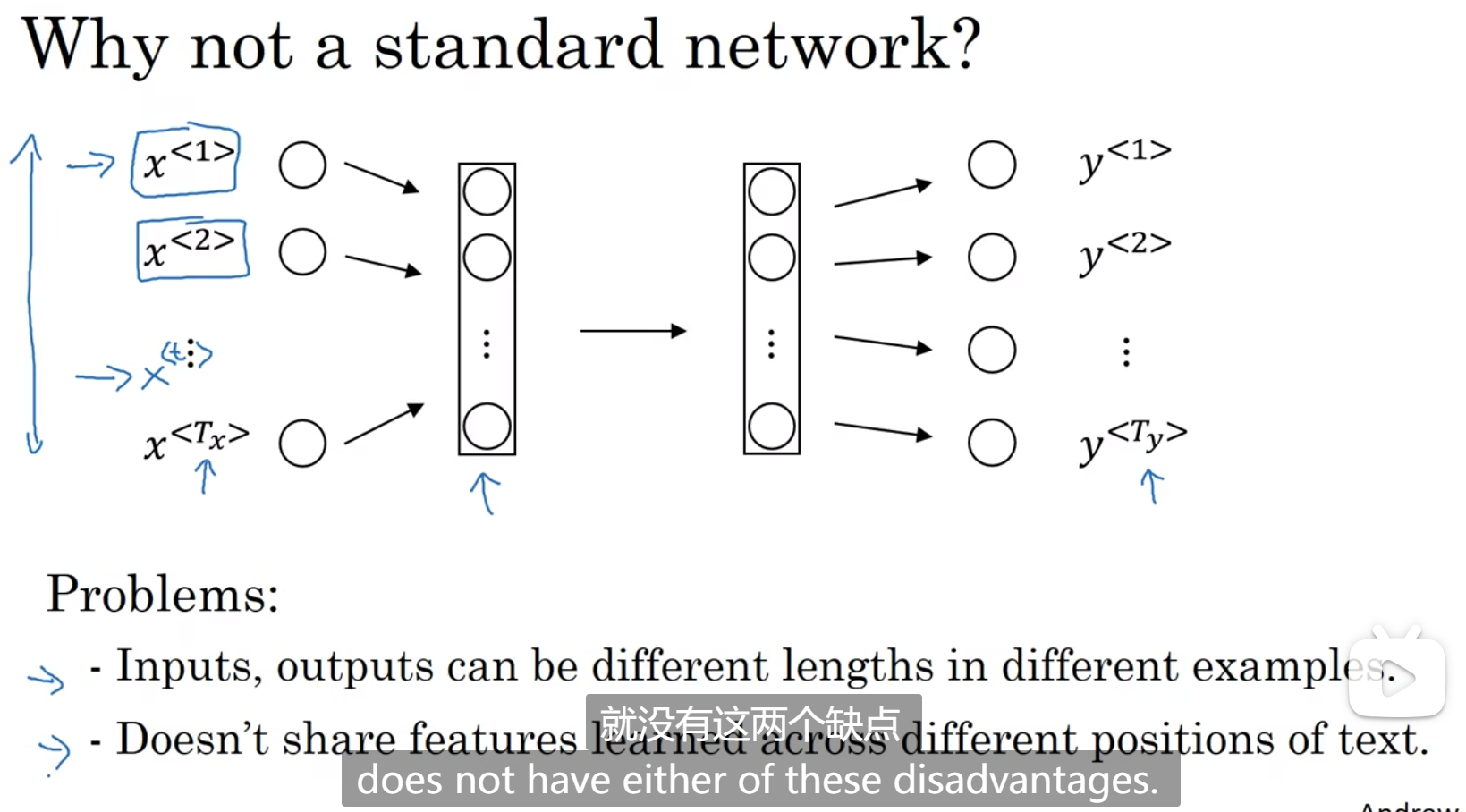
两个难点:
- 一个句子的长度不是固定的
- 希望得出来的结果是根据文本内容进行判断的,而不是单词位置,同时x可能是词表的映射,可能是一个维度很大的向量
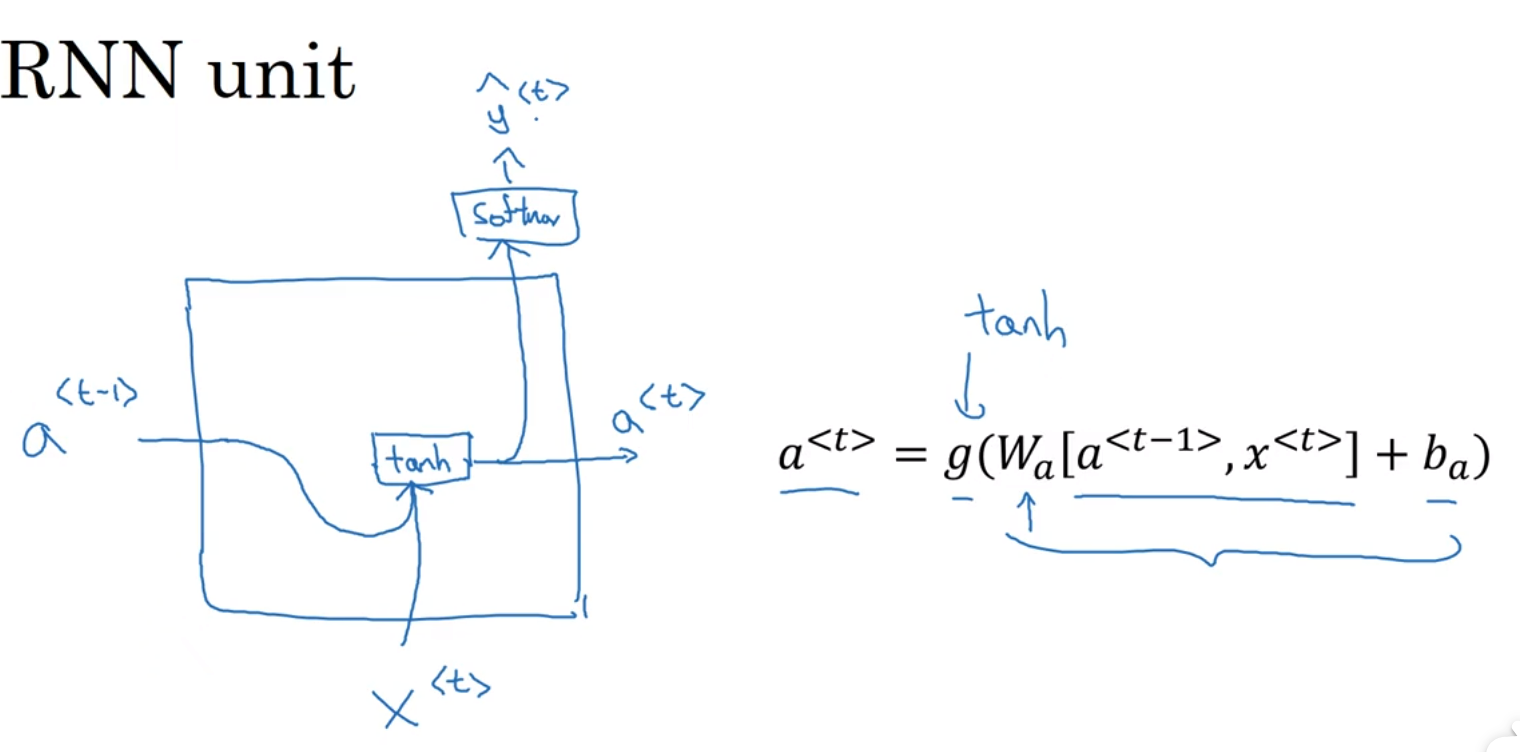
循环神经网络(这是表示一个单词一个单词做判断,但是单词之间不是独立的,第一个单词训练时,会用到初始变量a<0>,第二个单词判断时会用到第一个单词训练时产生的参数a<1>,也就是说,第i个单词判断时,会和前i-1个单词都有关,包括初始变量,输入时用到的参数时Wax,激活变量用到的参数是Waa,输出变量用到的参数是Wya,ax表示要乘以x计算出a,aa表示要乘以a计算出a,ya表示要乘以a计算出y):
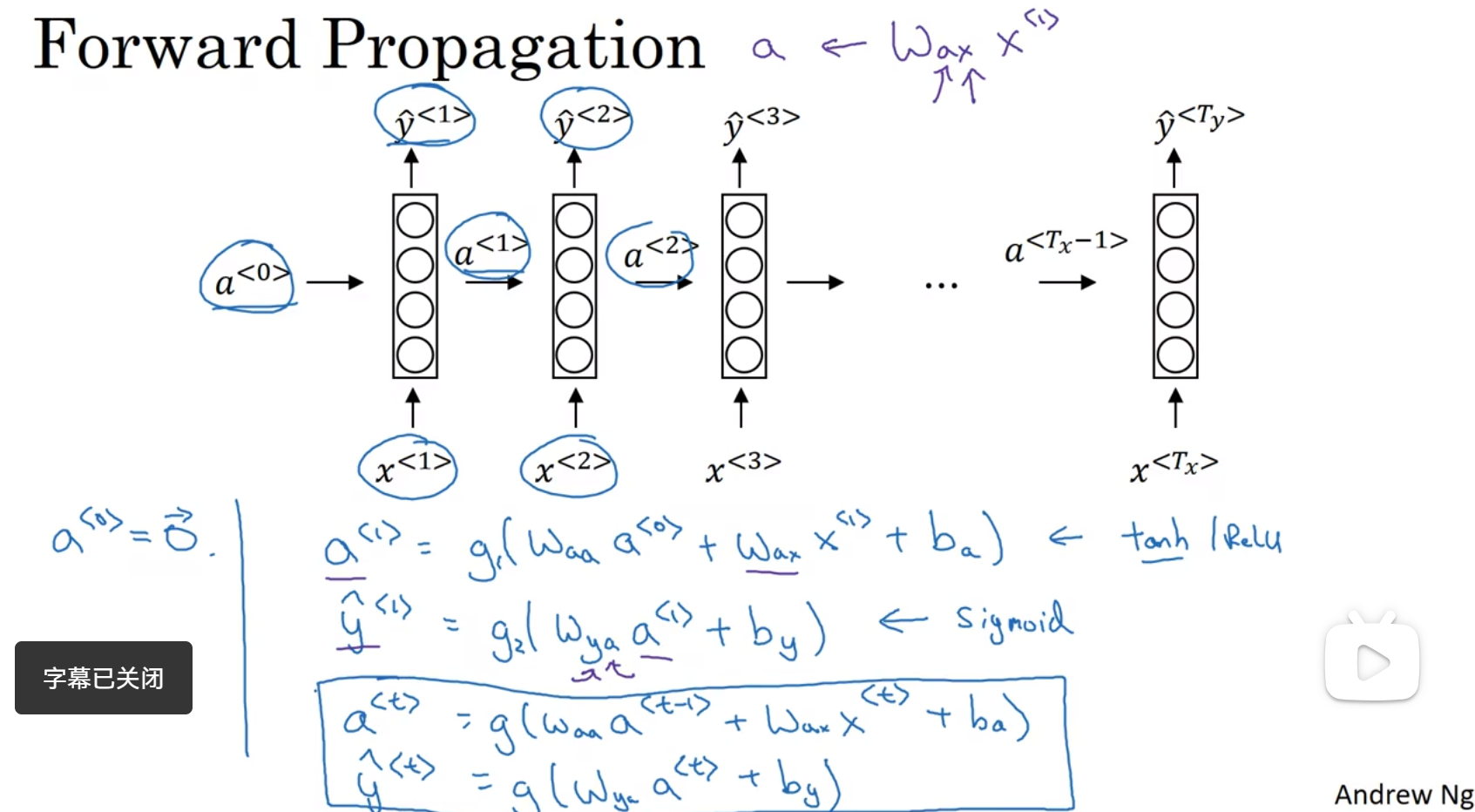
向前传播的过程,向前传播一般用tanh,有时候也用RELU
输出就看是二分类还是多分类
a
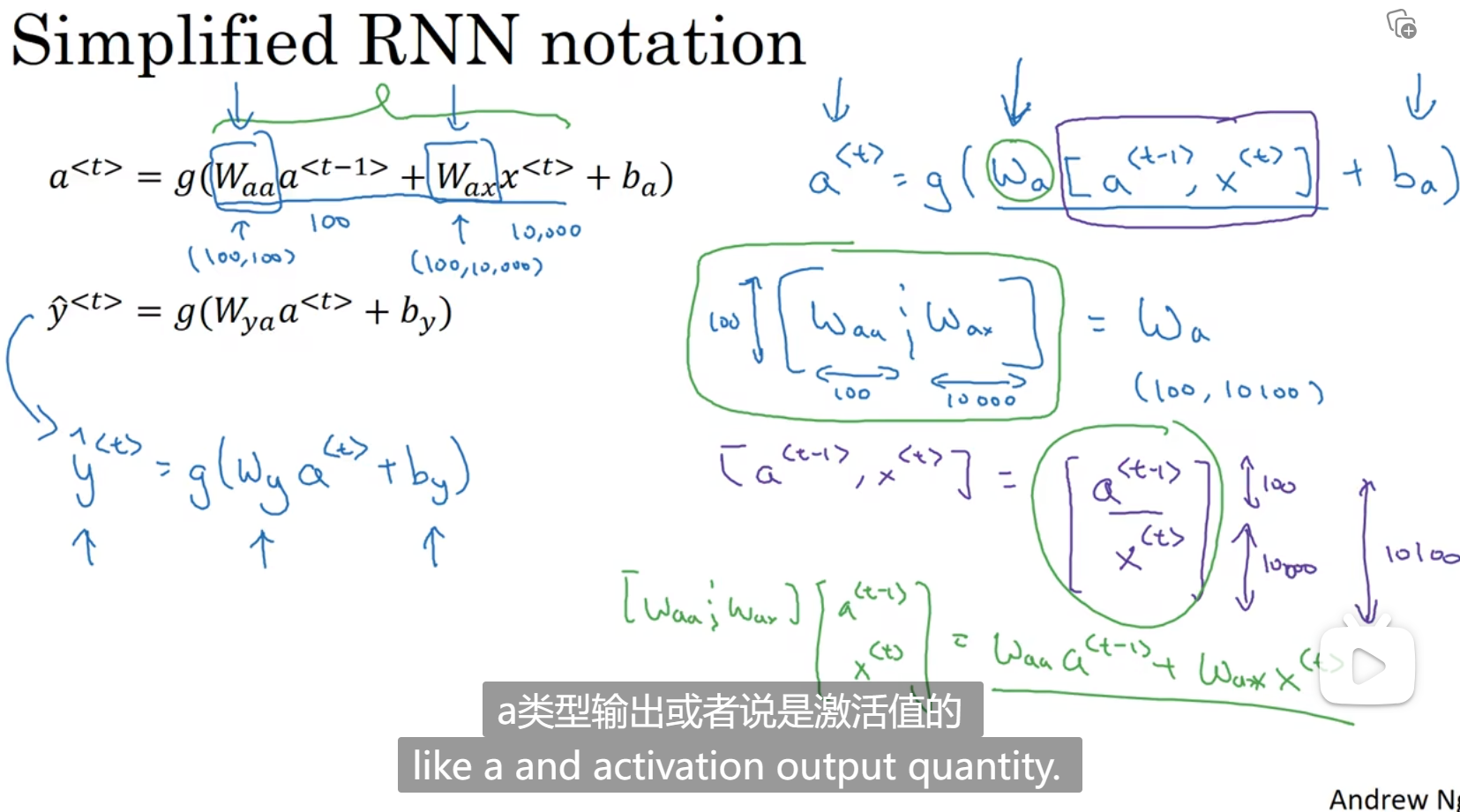
通过时间的反向传播
反向传播,用的参数都是一样的,然后算导数,算梯度:
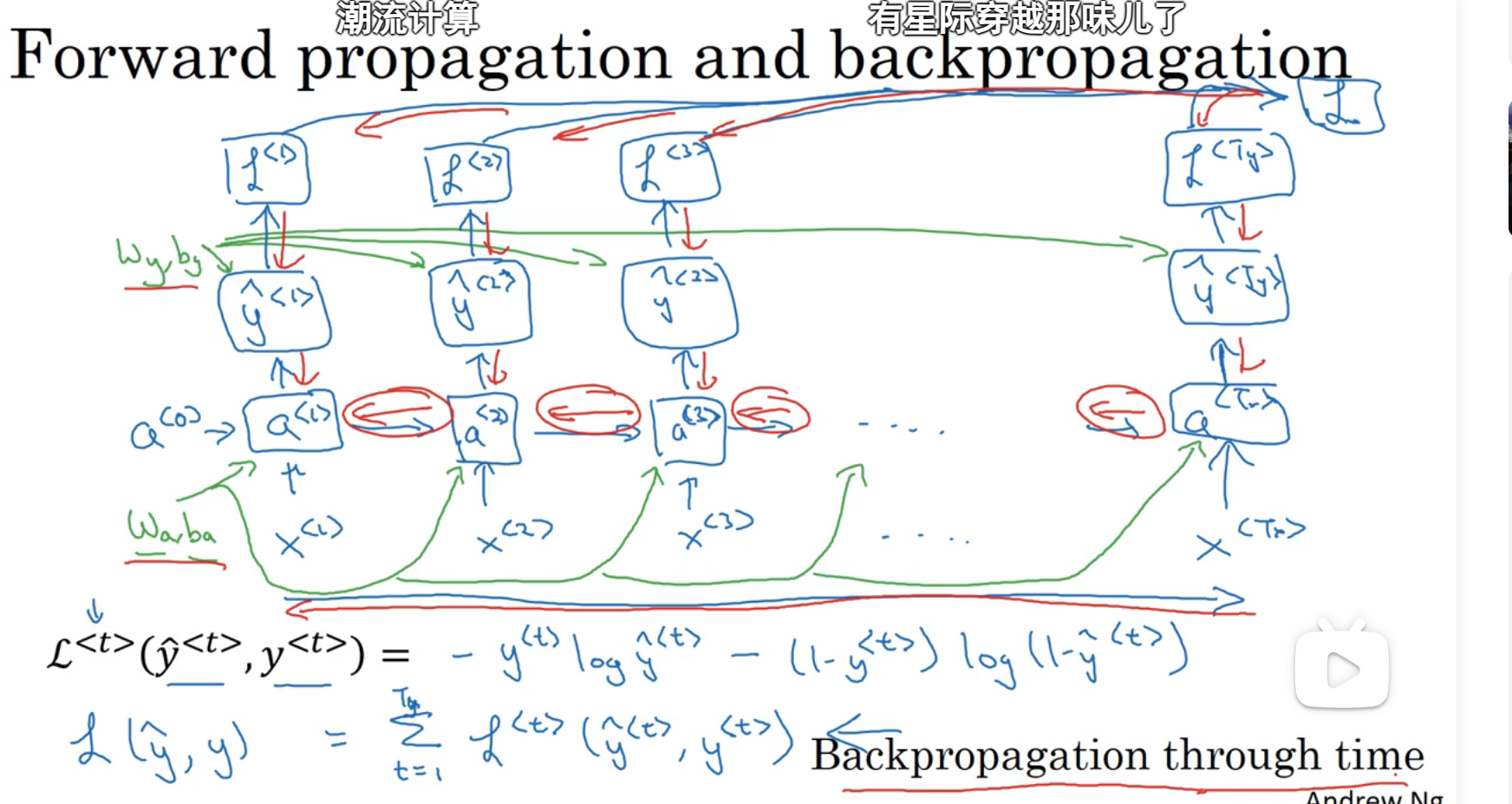
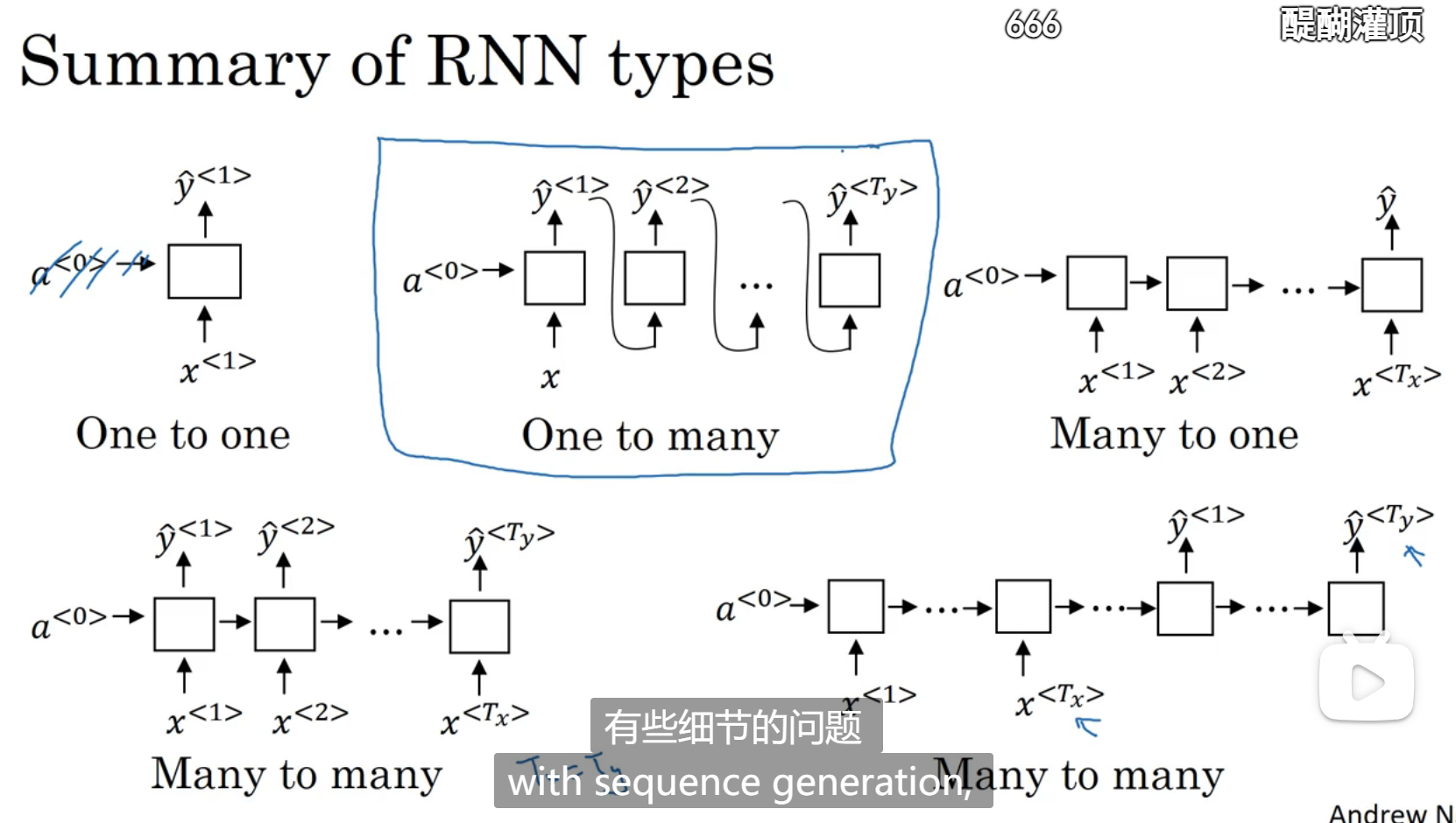
不同类型的循环神经网络
上面所讲的循环神经网络是输入维度等于输出维度(T_x=T_y)
下面介绍不等的情况
比如情感分类:

比如翻译:

多对一和长度相等的多对多:
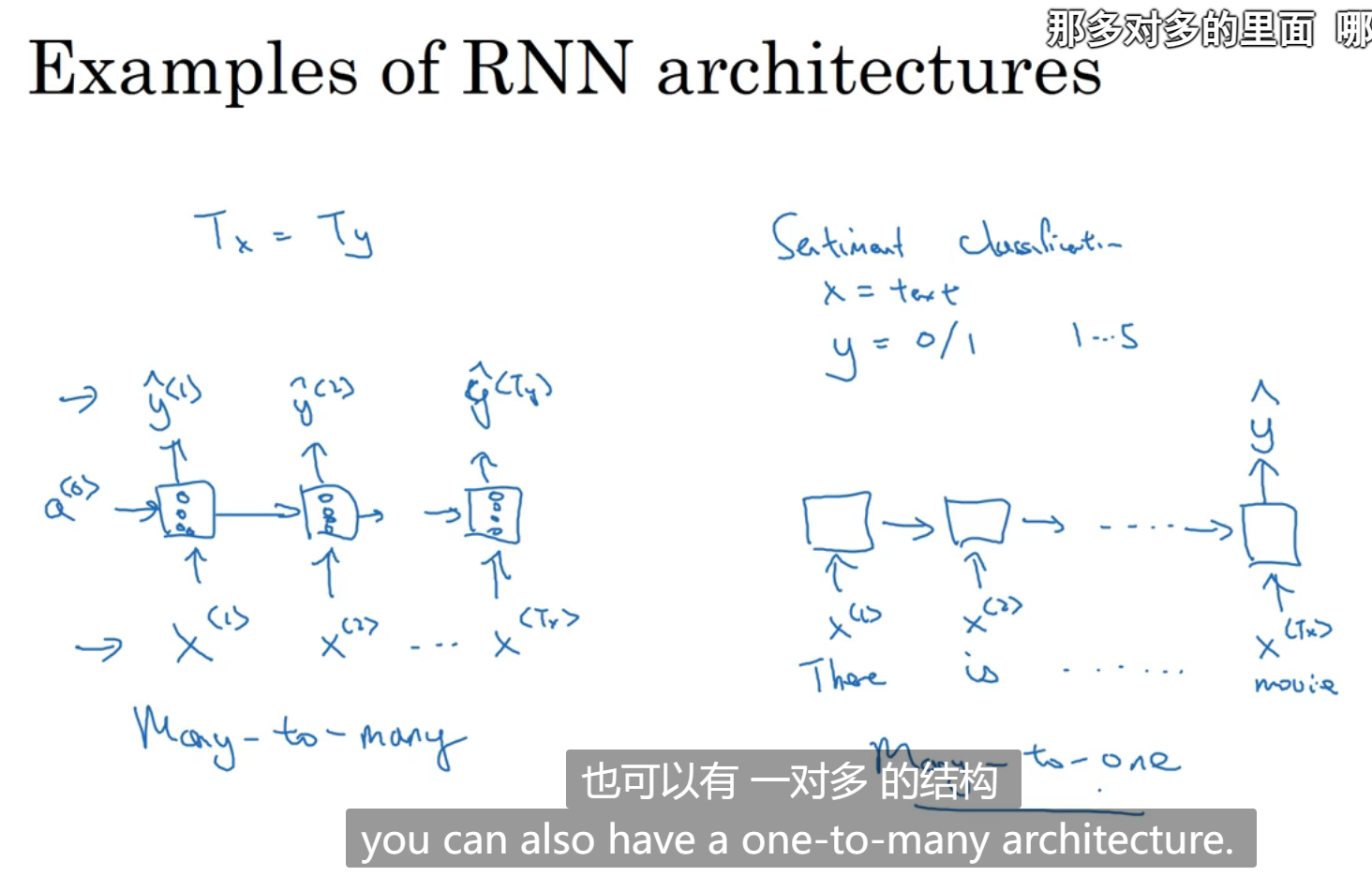
一对多(第一个输入对应一个输出,再自动生成输出)和长度不等的多对多(先获取所有输入,再进行输出)
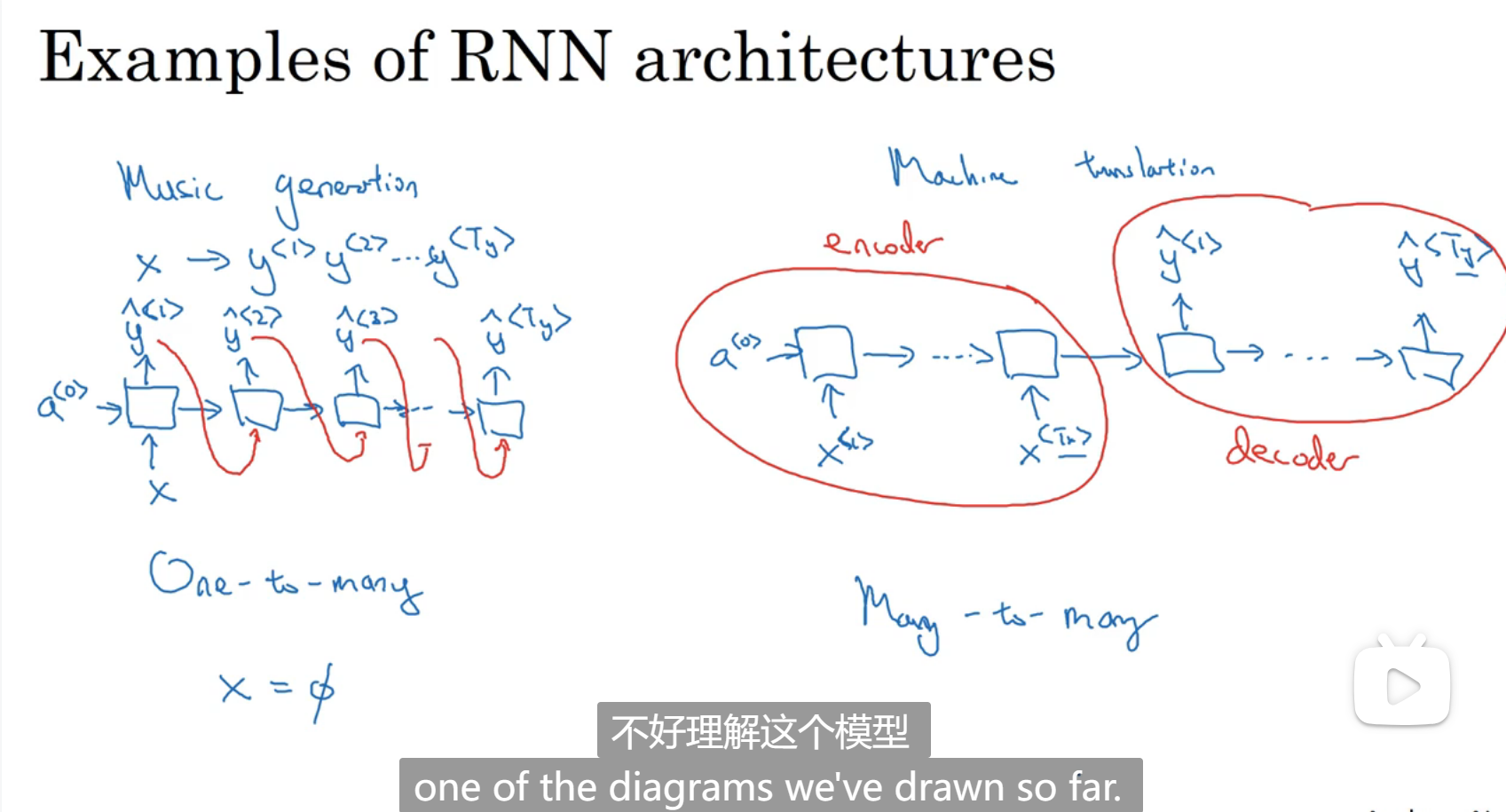
总结:
语言模型和序列生成
识别概率:
可以选择用

输出是softmax输出,告诉我是每个单词的概率是多少,感觉这里是自动生成

新序列采样
在训练了一个模型之后,要知道该模型完成了什么功能,就要进行新序列采样
输出是softmax,包含了输出是某个单词的概率分别是多少,
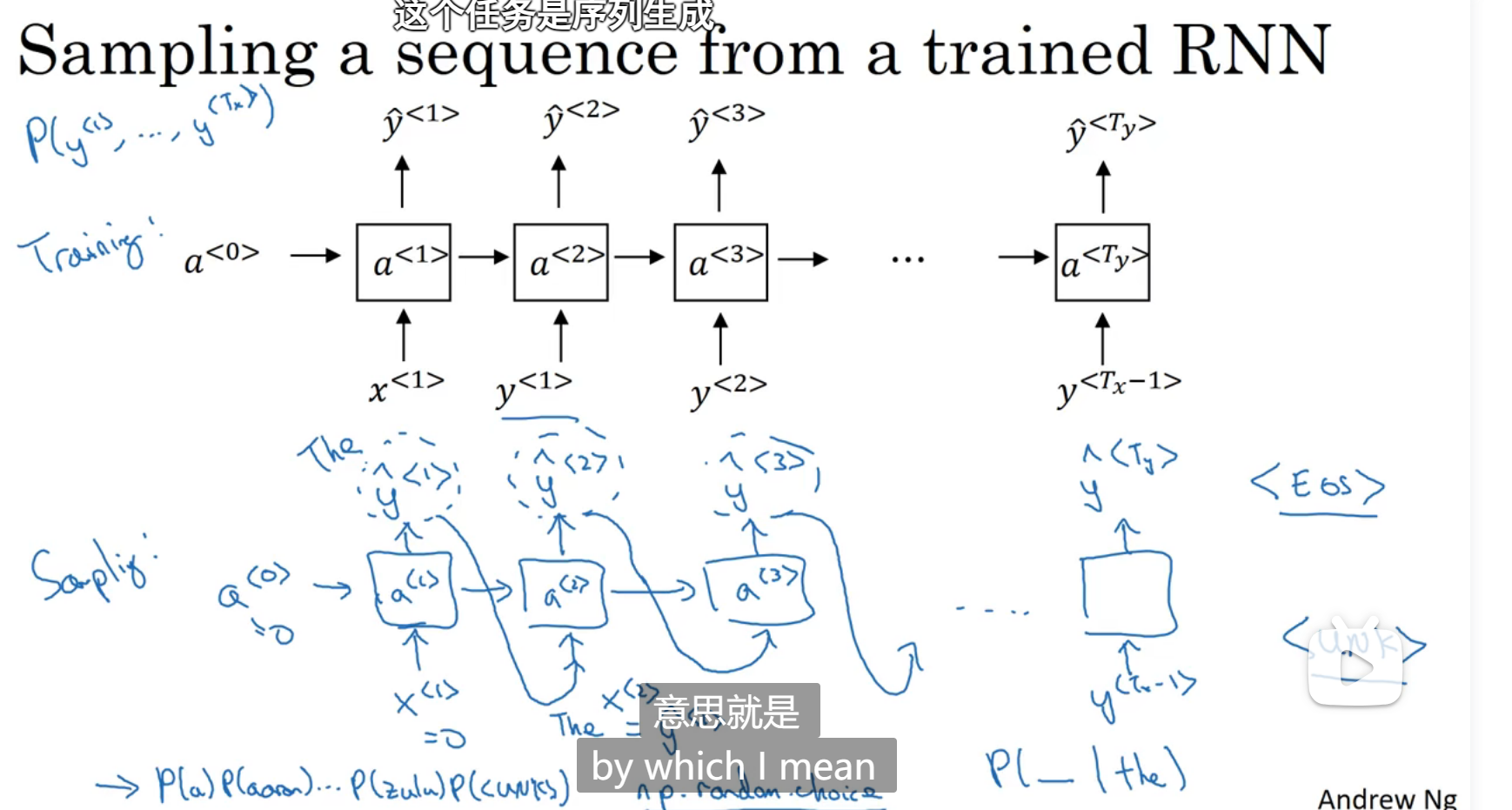
建立一个语言模型并去使用它,对训练出来的语言模型进行采样,比如给机器一串新闻,让他以某种人的语气输出来
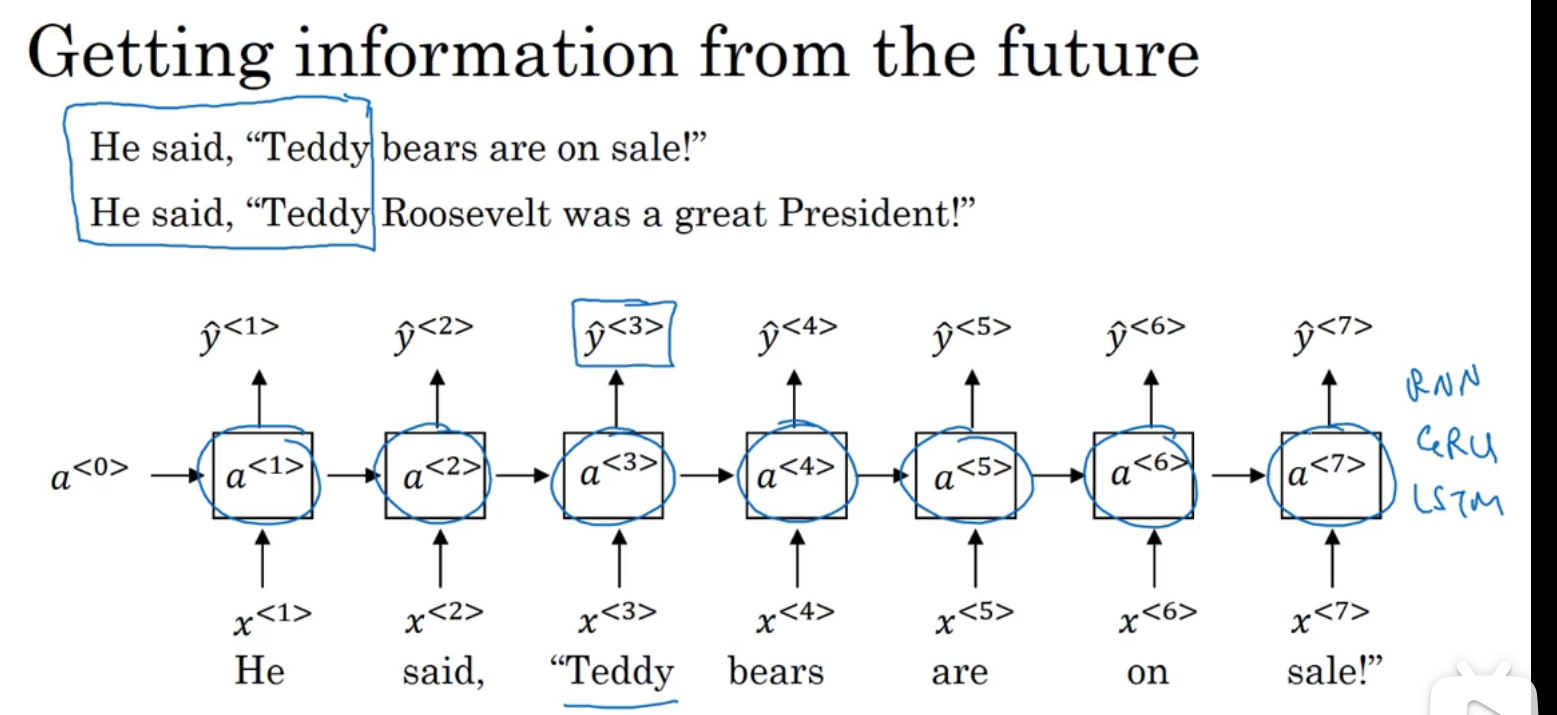
带有神经网络的梯度消失
对于一个很深的神经网络,很难靠影响前面的层来影响后面的层,所以对于一个句子,过于前面的内容很难影响到后面的句子,但是后面的句子可能就是依靠与前面的内容,所以基本的RNN有很多局部影响,但是还是很难做到影响,这是RNN的一个难点,梯度爆炸可以用梯度修剪处理,但是梯度消失很难
GRU
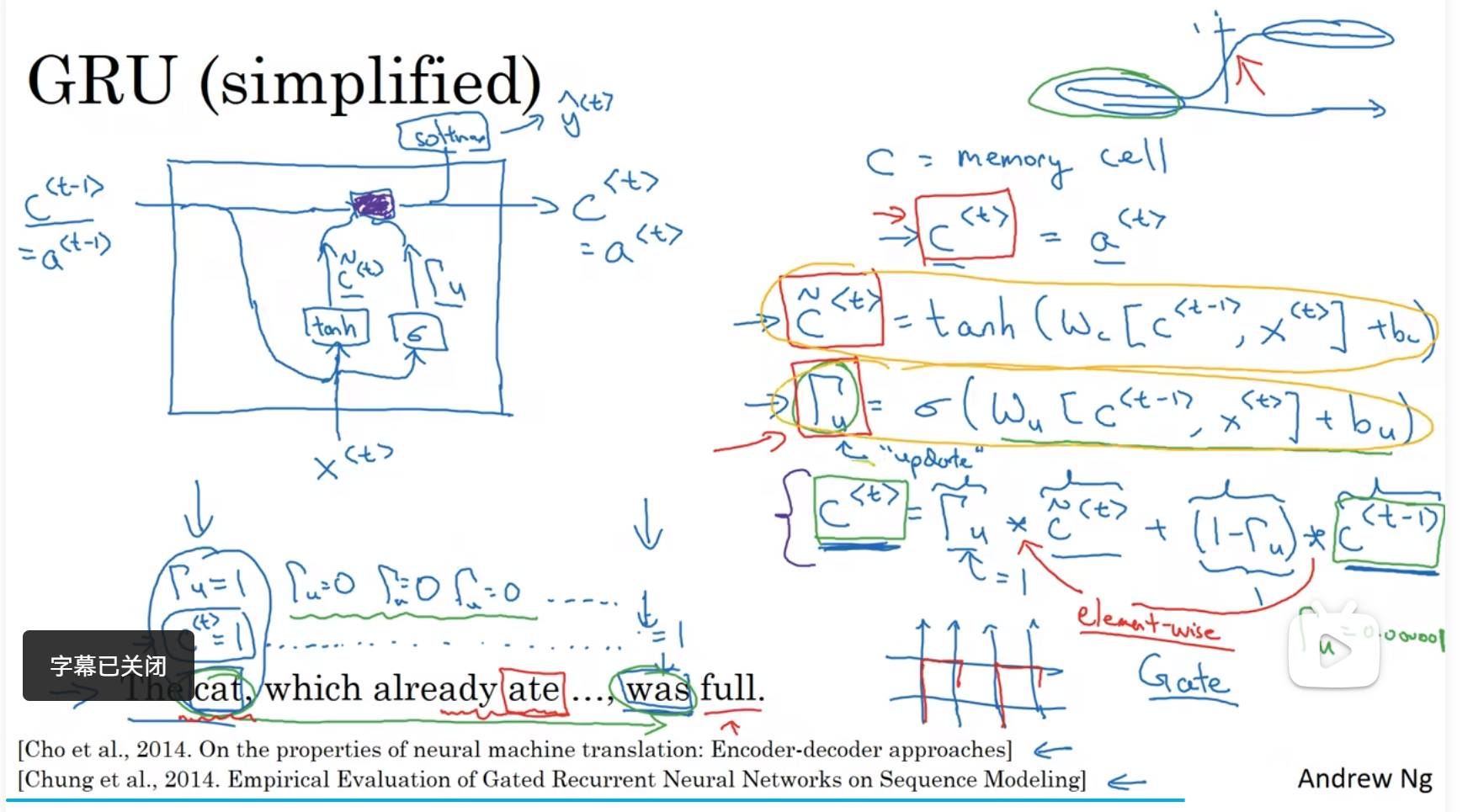
处理梯度消失:GRU(门控循环单元)
改变了RNN的隐藏层,可以更好的捕捉深层连接,
RNN隐藏层:
GRU会产生一个c:记忆细胞,提供了记忆的能力
因为当前time step输出的激活值会随着时间推移,由于后层各种输入和计算逐渐对后层失去影响,所以想用一个记忆单元保存当前时刻的激活值,在后层计算时施加影响。也就是说at会被替换成ct
有一个门,他会记录一个记忆细胞,并决定什么时候更新这个记忆细胞
如图所示,ct和at的值实际上是一样的,ct就是记忆细胞,门是用来决定是不是要更新ct,就如下方ct的函数,门的值也是通过ct-1和x的值决定的,用的sigmoid方法,输出只有0-1,用来觉得ct和ct-1的关系,以及该层ct_hat的值,然后算出yt
另一种GRU:门r表示ct-1和ct的相关性,也是为了应对梯度消失的问题:

LSTM(长短期记忆)
增加了门f:遗忘门
有三个门,更新门,遗忘门,输出门,门值都在0-1之间

如果门不止和a x有关,可以自己添加 如下面那一排所示,c0很容易传递下去
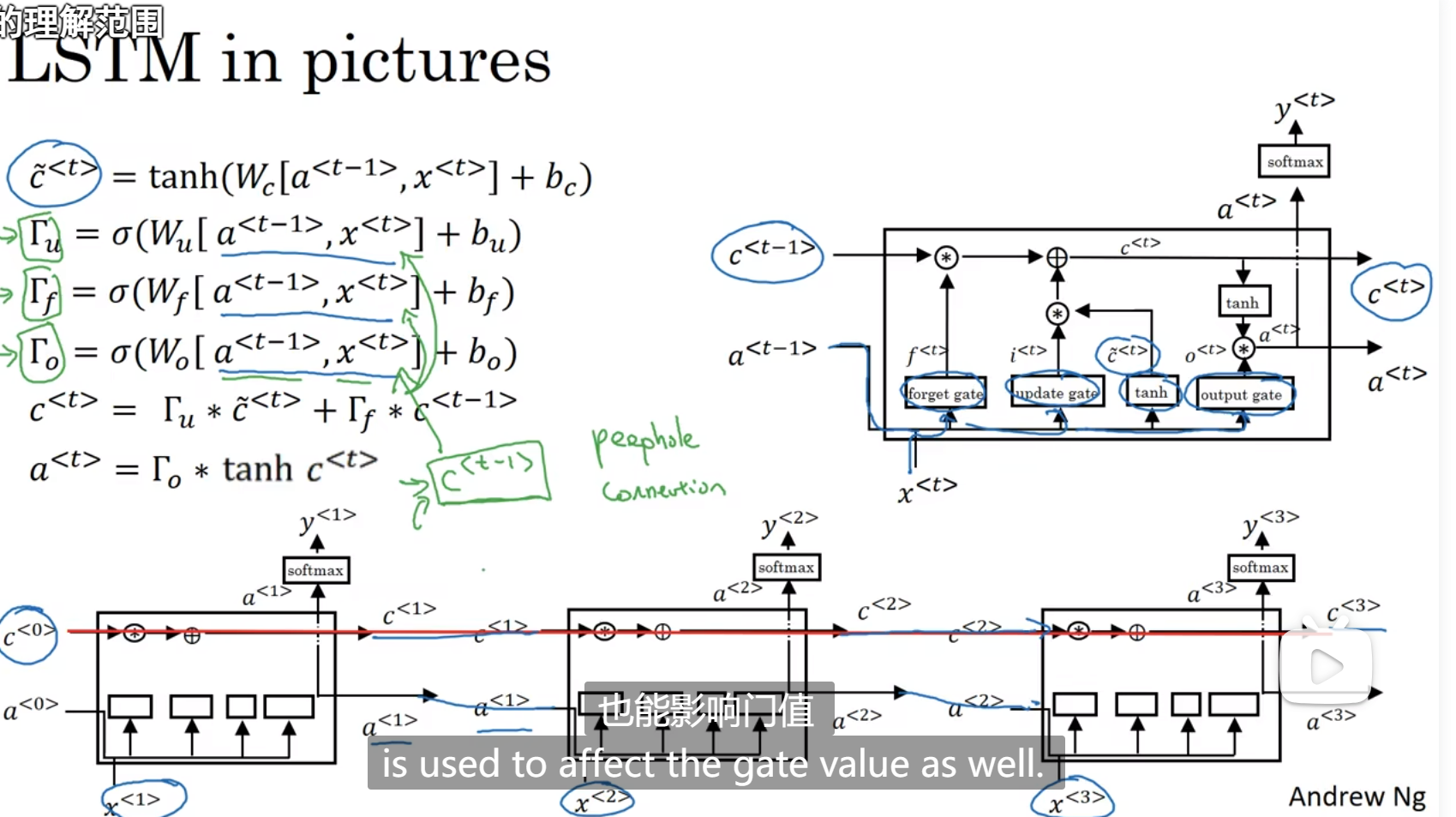
推荐LSTM
双向神经网络
单项示例:可能是RNN块,GRU块,LSTM块:
输出就和正向传播和逆向传播参数都有关
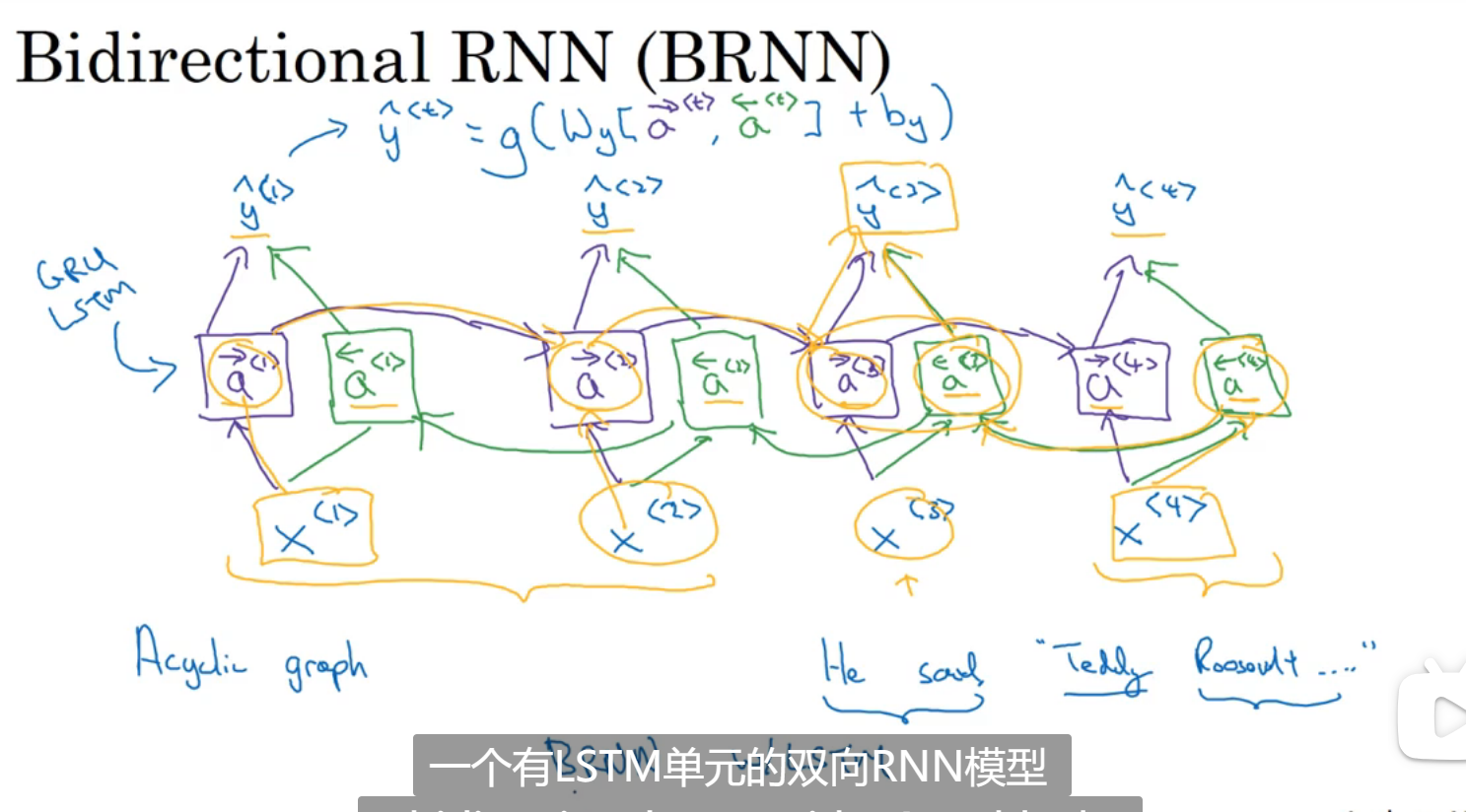
需要完整的句子才能进行预测
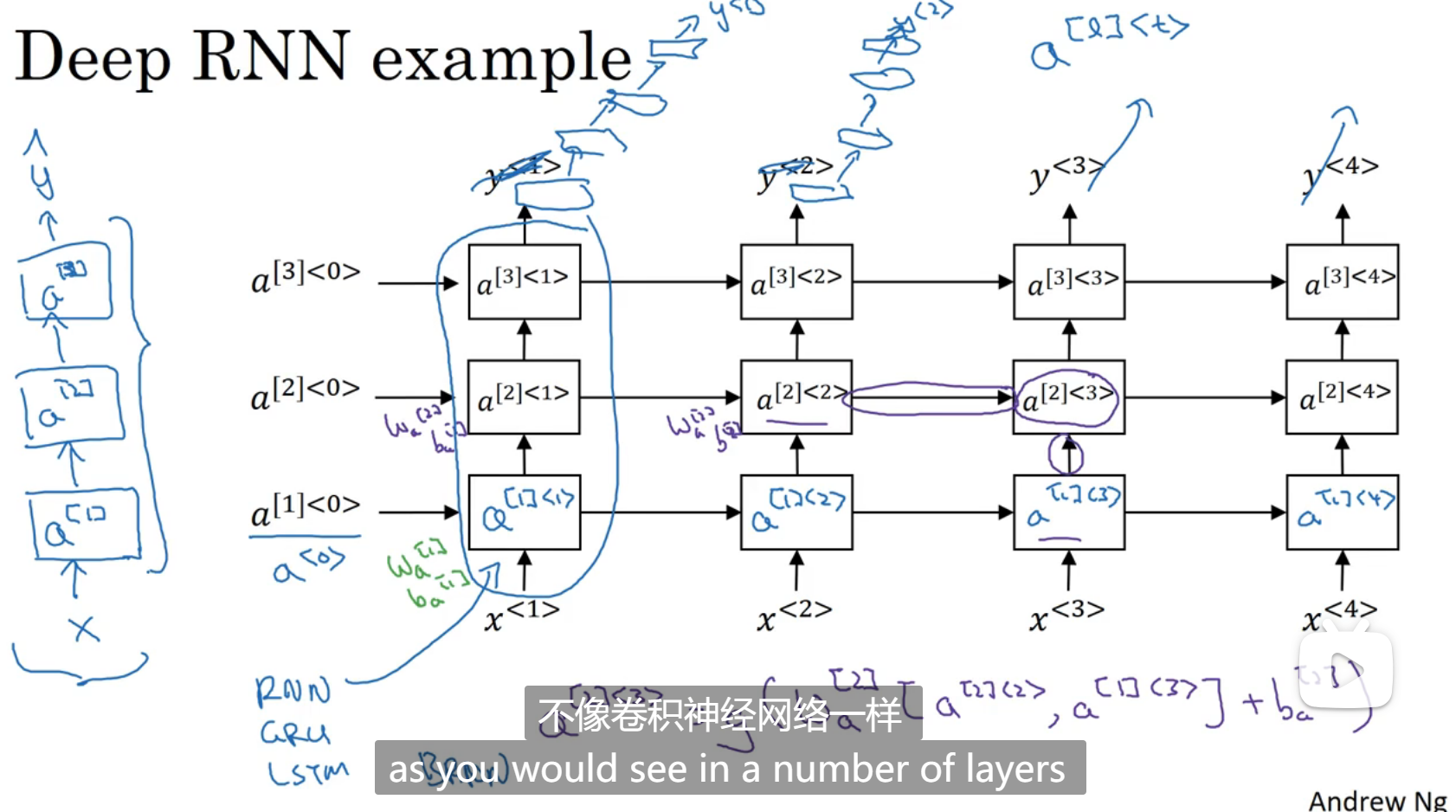
深层循环神经网络
通常我们会把RNN的多个层堆叠起来,构建更深的模型
[]里面是第几层的参数
<>里面是第几个单词或者字符
深度学习week5_1
install_url to use ShareThis. Please set it in _config.yml.


