深度学习week5_2
版权申明:本文为原创文章,转载请注明原文出处
深度学习week5_2
词汇表征
将RNN GRU LSTM用于自然语言处理(NLP)
词嵌入:让算法自动的理解一些类似的词
我们上周的理解是这样的,(one-hot)将所有词都存在一个词表里面,但是这样就会导致词和词之间是独立的,比如如下图的情况,orange和apple本来是很相近的两个词,比如下面两个句子都应该学习到后面的一个词是果汁,因为苹果和橙子是相近的两个词,但是如果相互独立就很难这么学习到:
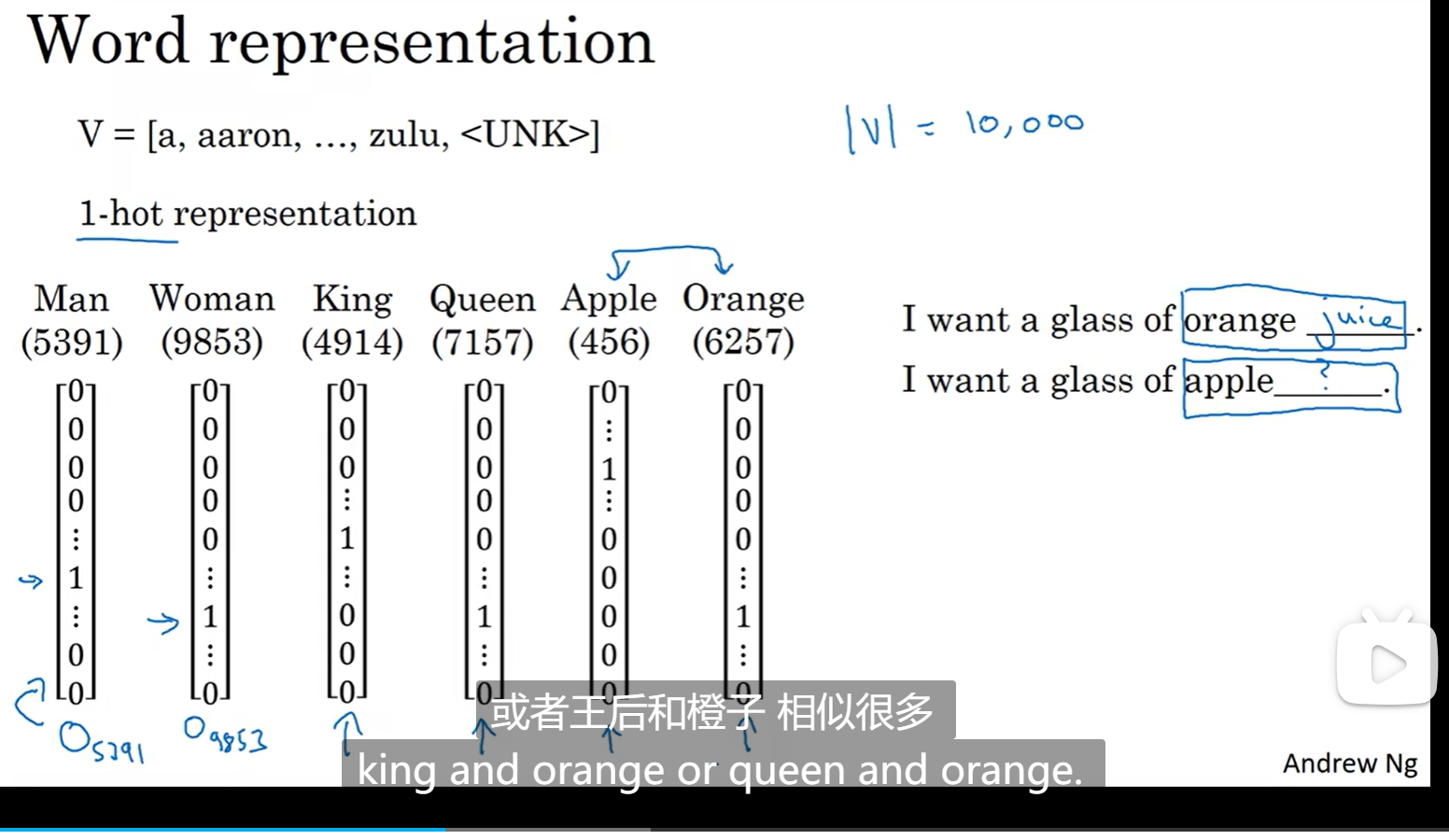
现在变成特征化表达:
可以将多维的特征降维(t-SNE),有点像k聚类
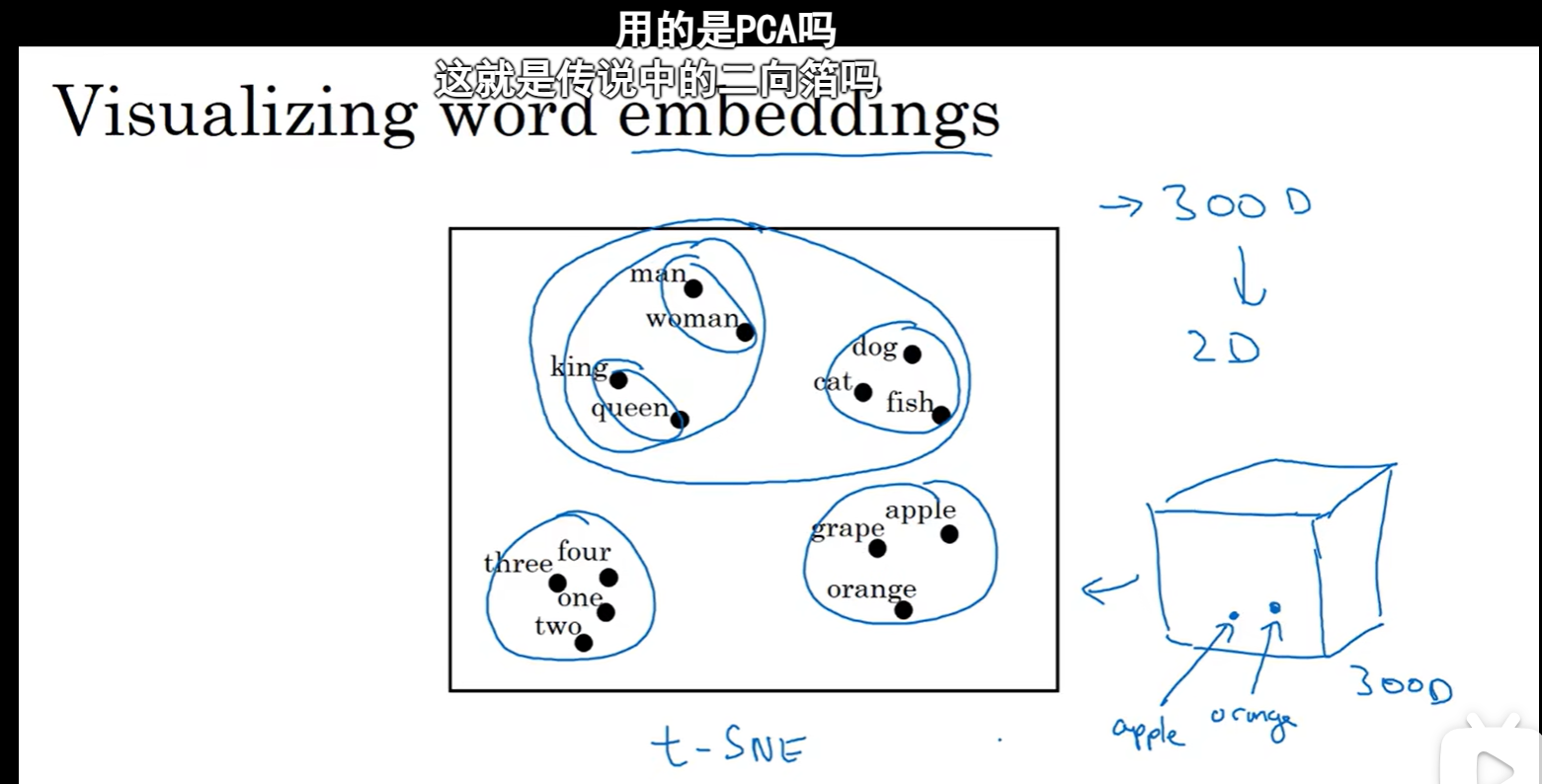
使用词嵌入
如果遇到一些不常见的词,而自己的训练样本又比较小,可以考虑迁移学习,用网上已经学习好的词嵌入模型
当训练集越小时,词嵌入效果越好,词嵌入基本流程:

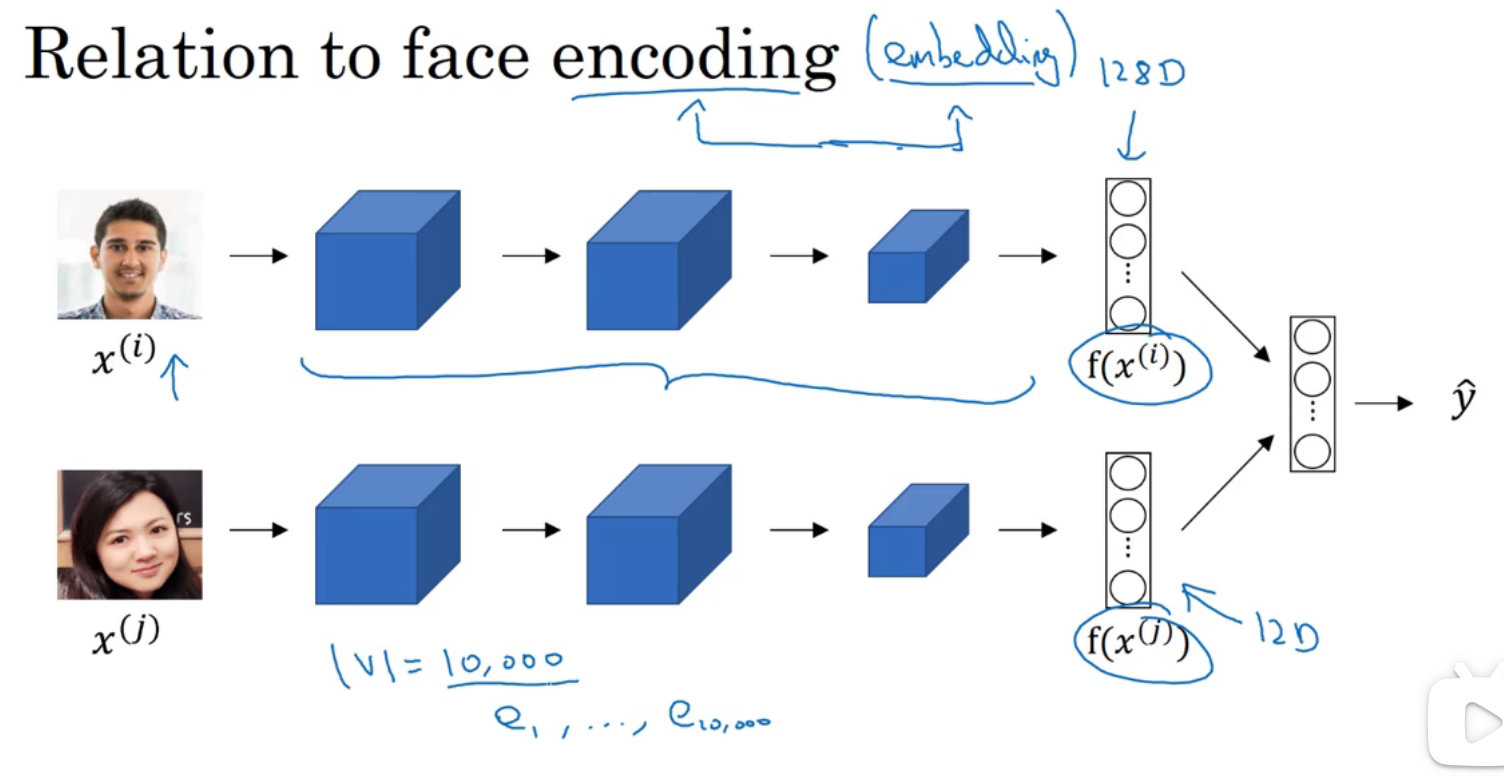
和卷积网络所学到的比较两张人脸有一定相似性
词嵌入的特性
词嵌入可以帮助实现类比推理
比如我们知道男人对应女人,怎么让机器推导出国王对应王后呢:比较它们的差

将要求的单词设为e_w,求相似度:
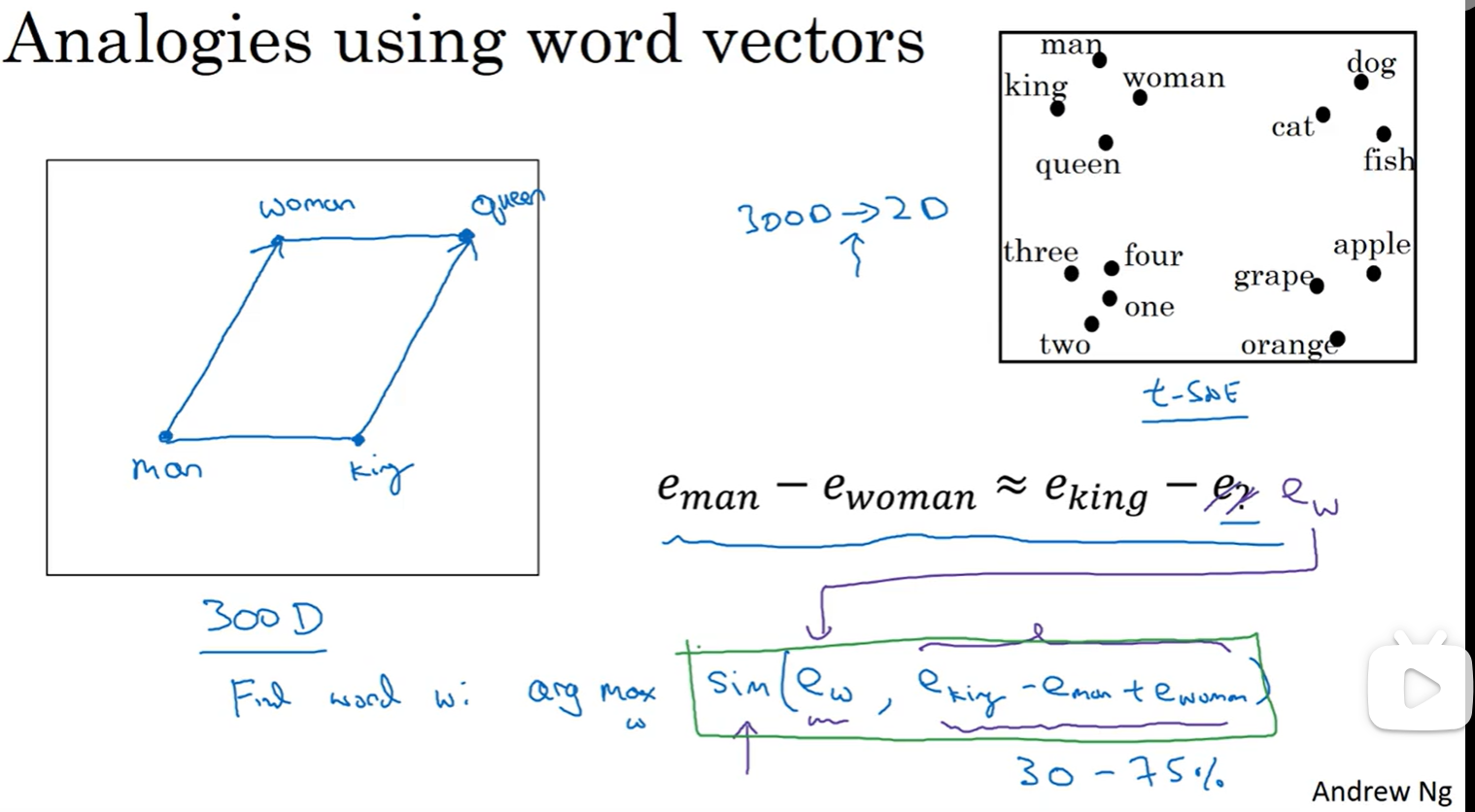
余弦相似度,感觉相当于一个向量是一个点:

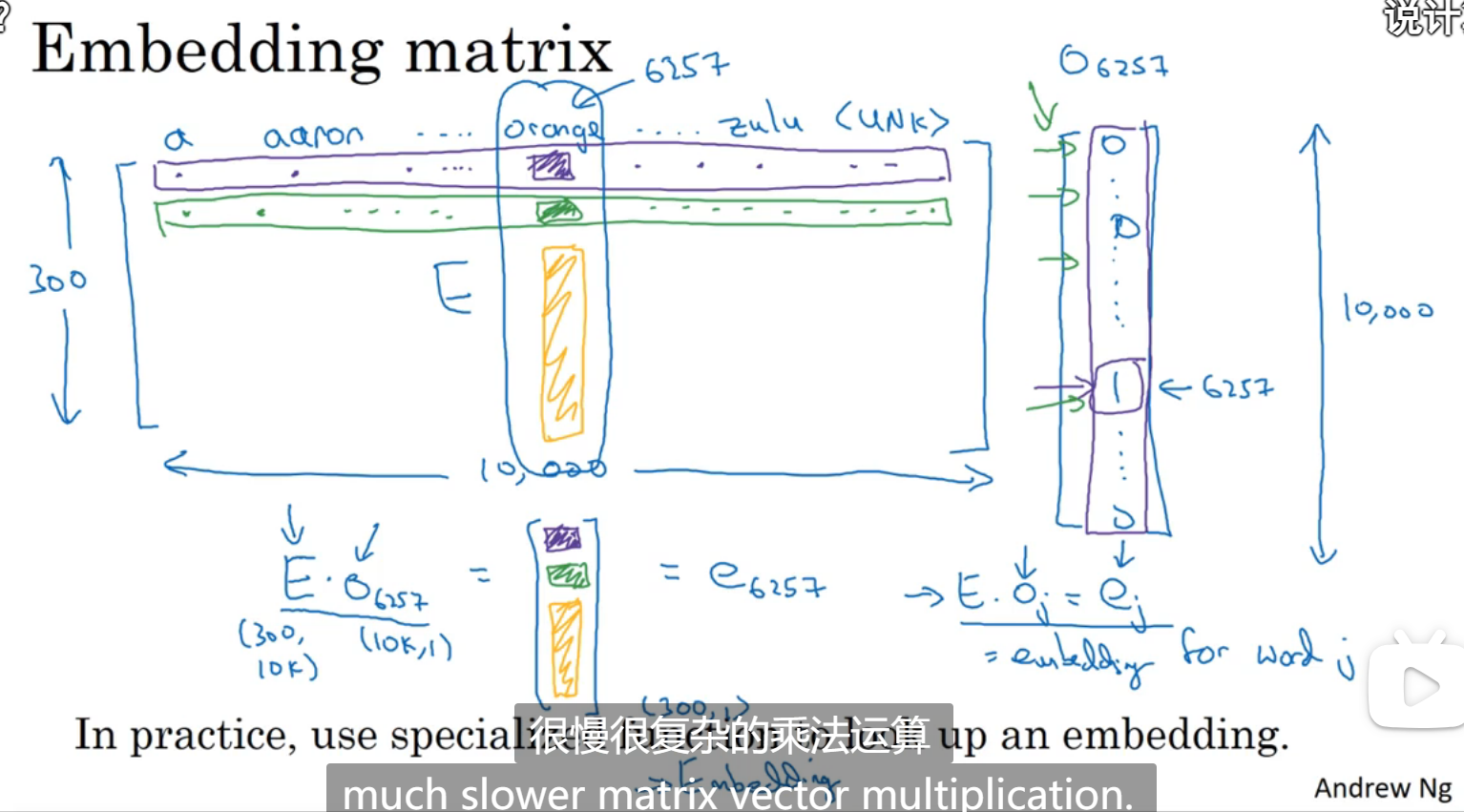
嵌入矩阵
当利用算法学习一个词嵌入的时候相当于是在学习一个嵌入矩阵
相当于总共有300个特征,每个单词都是一个特征,300维,把这个矩阵叫做嵌入矩阵E,每次我们要取某个单词的特征的时候,我们用特征 * one_hot的值,就可以得到一个300维该单词的特征
学习词嵌入
神经网络结构:
E是嵌入矩阵,o是one_hot,算出e是该单词的300维的特征向量,然后输出,参数可以通过梯度函数调整,很好的学习两个特征值相近的词,可以规定只从前面几个词学习
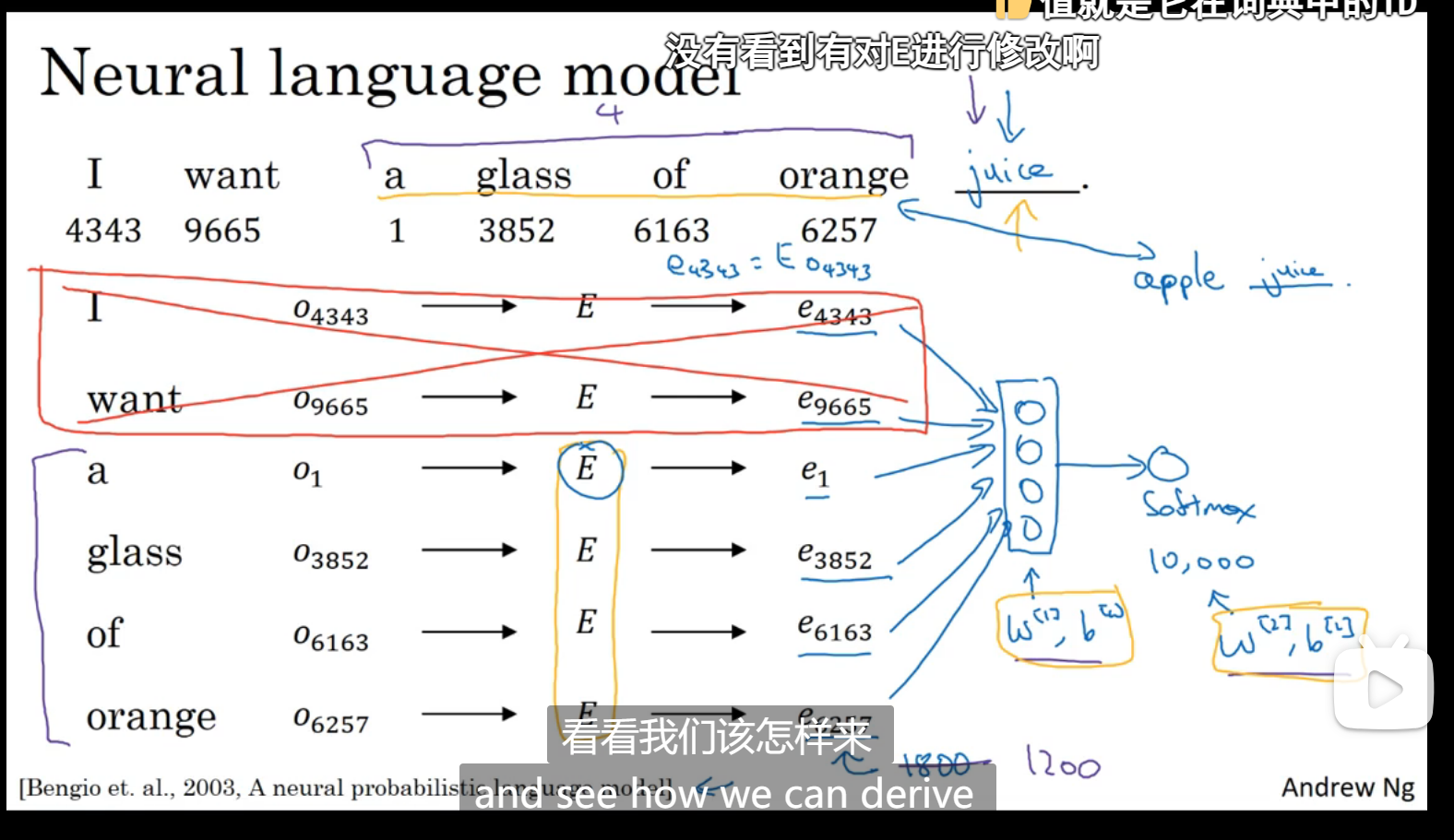
如果我们想训练出一个语言模型,只选择相邻几个单词学习是一种不错的选择,如果我们想学习其他嵌入算法,可以选择另外的单词学习

Word2Vec
skip-grams(感觉像是训练两个邻近的单词的对应关系,上下文某个单词->目标单词):

简单模型,输出是一个10000维的向量,和one_hot一样:
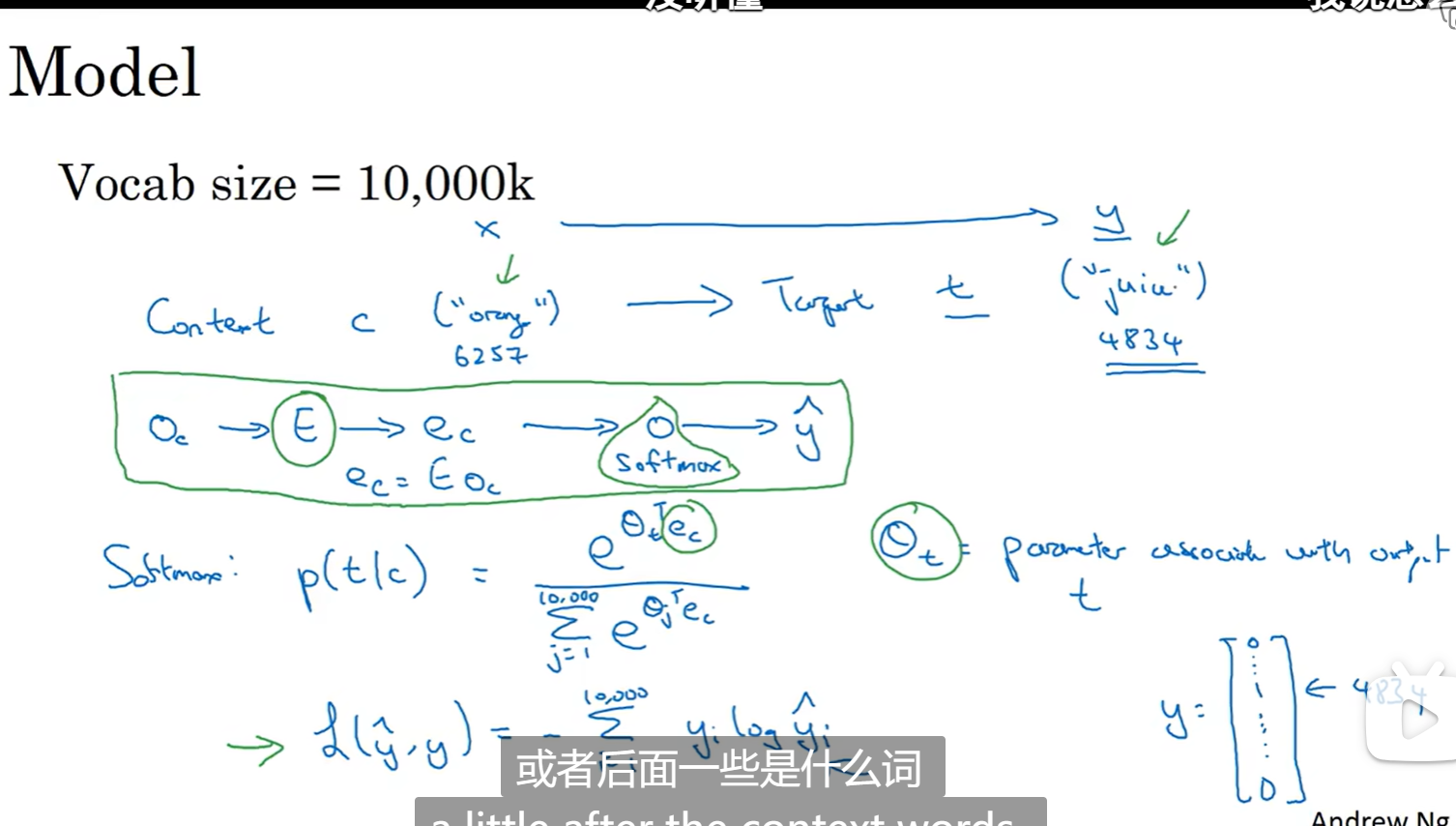
强迫算法去做预测,算法只能根据词嵌入矩阵来预测,然后告诉算法你算错了,算法就自己去修改词嵌入矩阵了
但是直接这样计算softmax,由于维度已经10000了可能更高,算法效率低,可以考虑采用分级softmax分类器(二叉树),使用的树,常用词在顶部,不常用词在深度,方便查找,通常不是平衡的二叉树

负采样
构造新的监督模型
先随机选择一个单词作为context,然后在近10个单词中选择word,设为正样本,然后再从词表中随机找k个单词,将这一组设为负样本,监督学习,最后的输入就行x,预测y,预测他是正样本还是负样本

之前就需要算10000维的softmax,这里就不需要,将输入应用到10000个神经元,每次只更新k+1个,这里k是4,用得出来的正样本和负样本去进行迭代

怎么进行负采样(怎么随机选择负采样的word,图下是比较常用的方法):

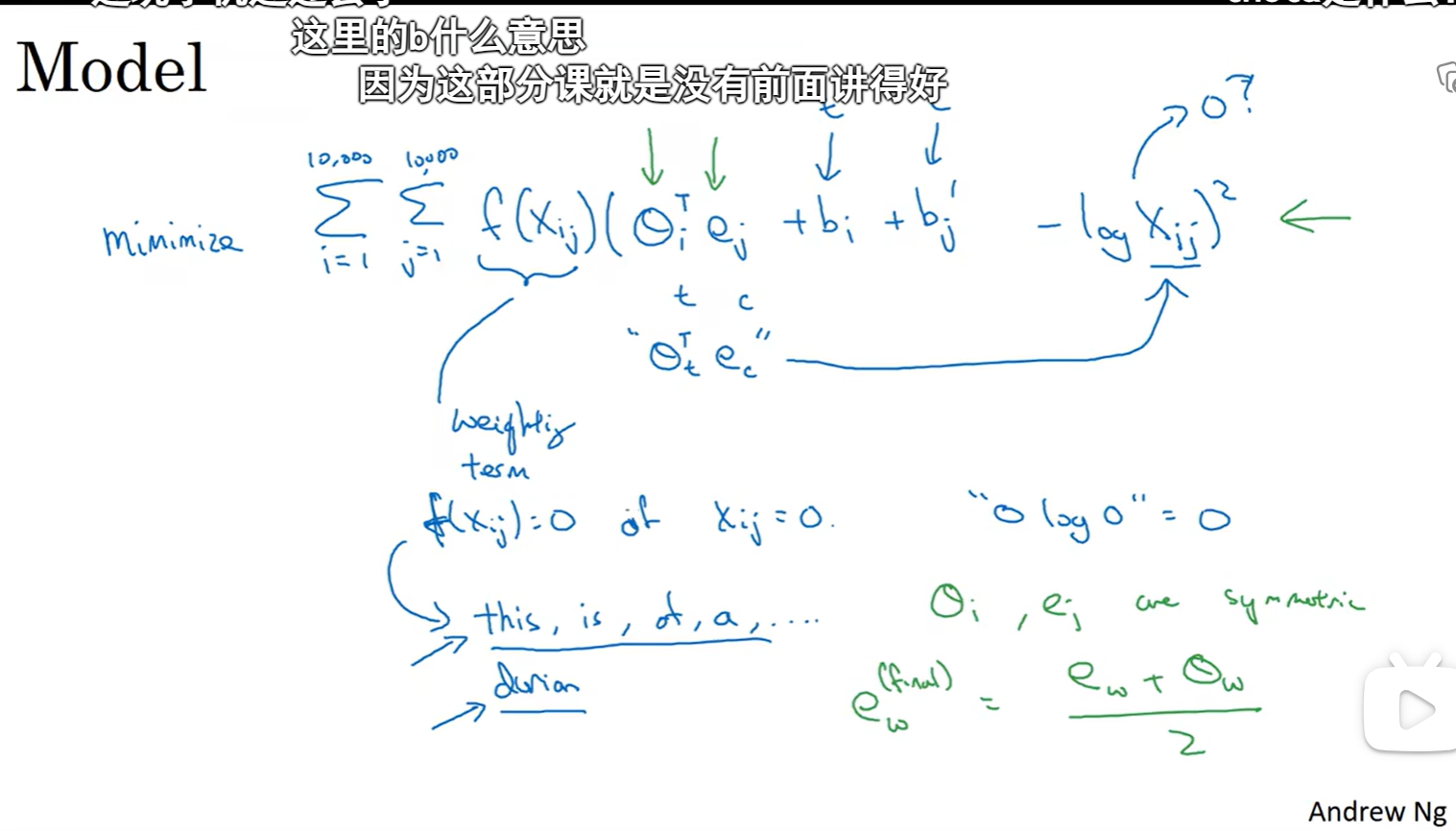
GloVe词向量
Xij是一个能够获取单词i和单词j出现位置相近时或者彼此接近的频率的计数器

本质是用词嵌入矩阵去构造一个网络去预测两个词同时出现的频率,但是我们并不需要这个网络,而仅仅通过网络来训练词嵌入矩阵
每一个可能的目标词有一个参数向量\(\theta_{t}\)和另一个参数向量\(e_{c}\)
实际上最后通过网络的到这些向量特征不是简单的Gender这些特征
各轴之间可能有关联

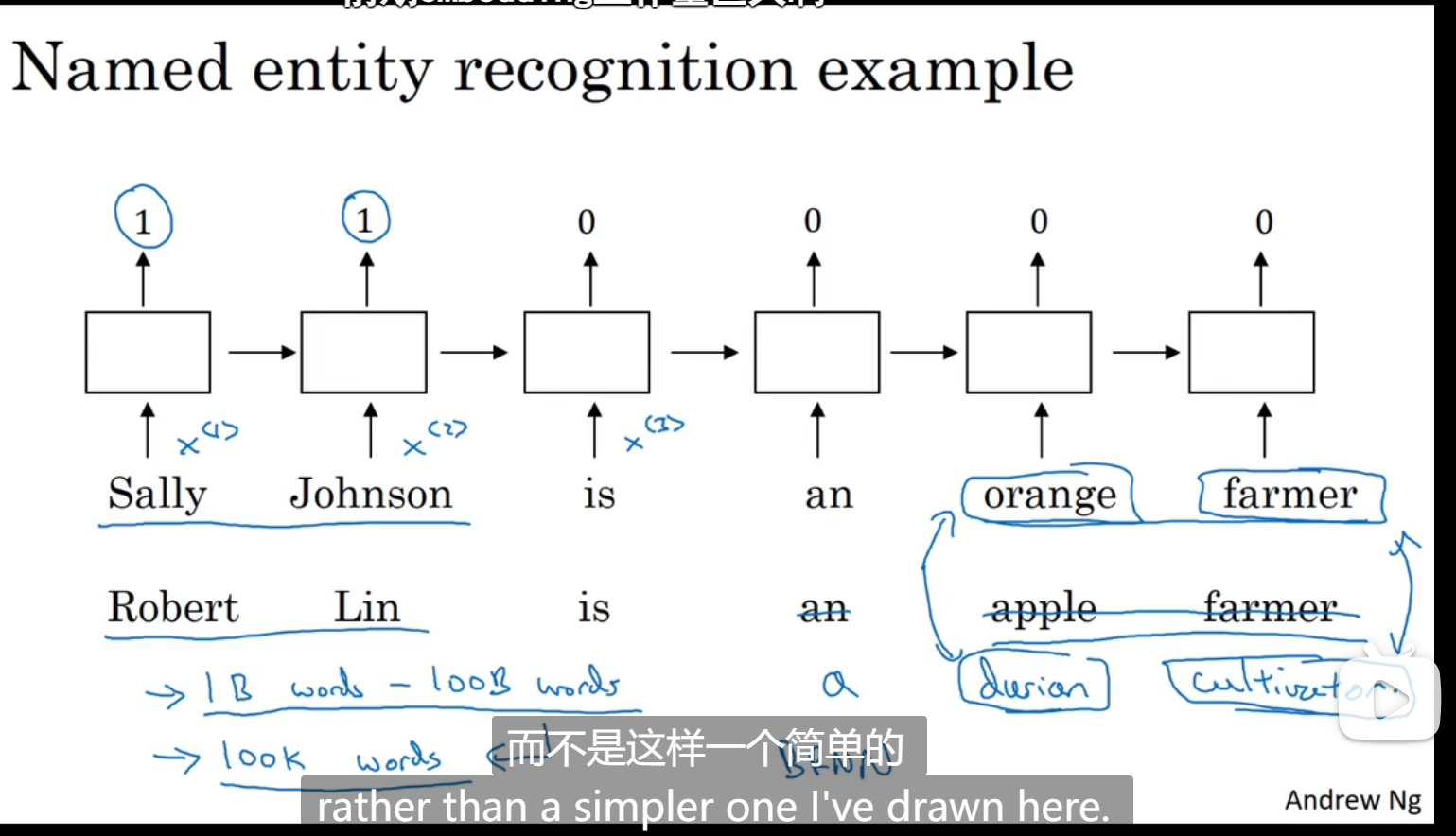
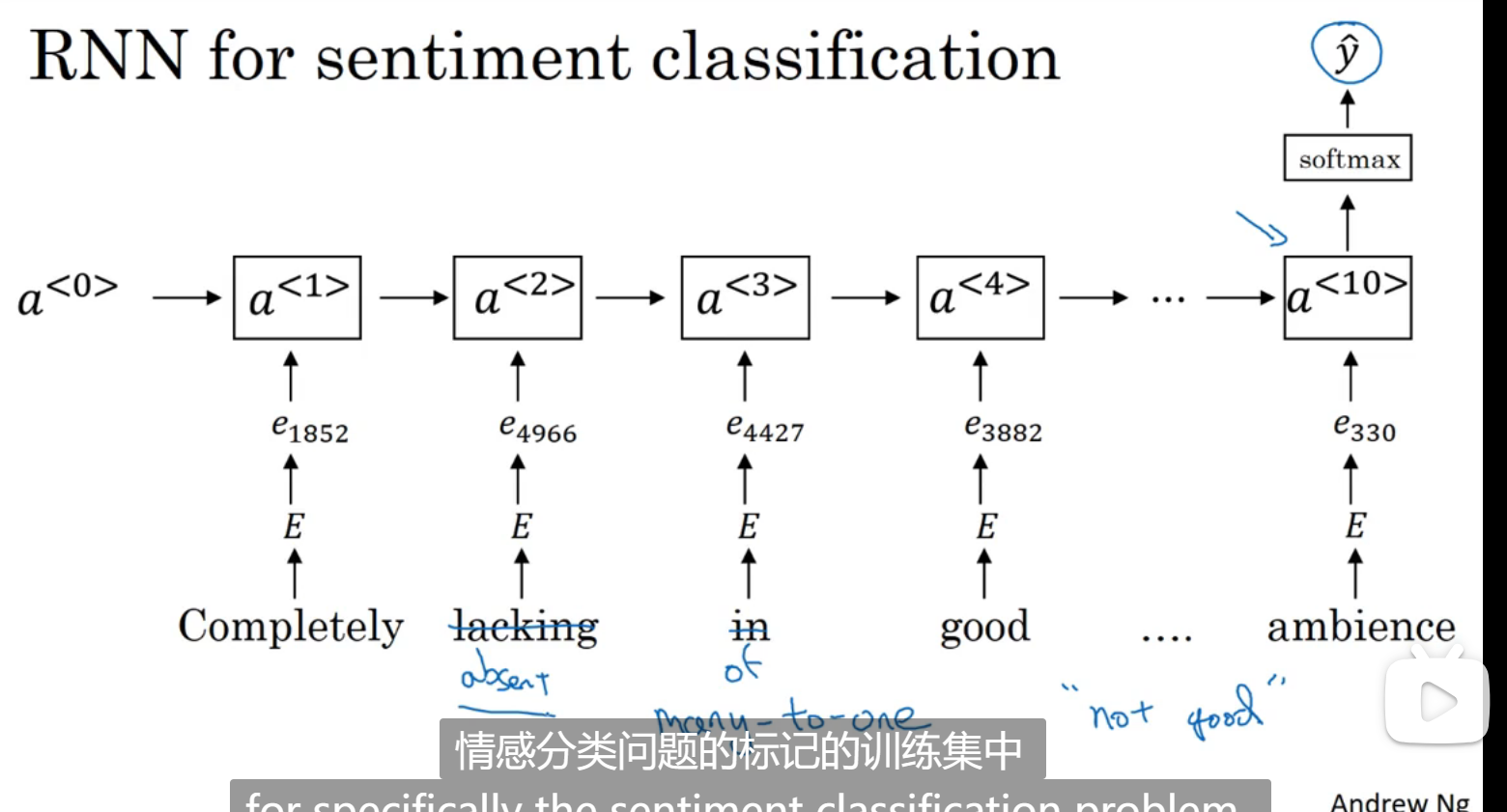
情绪分类
最大的挑战是标记的数据集不够多
用所有特征相加求平均值的方法(缺点:没考虑词序):

解决方式(用RNN做):
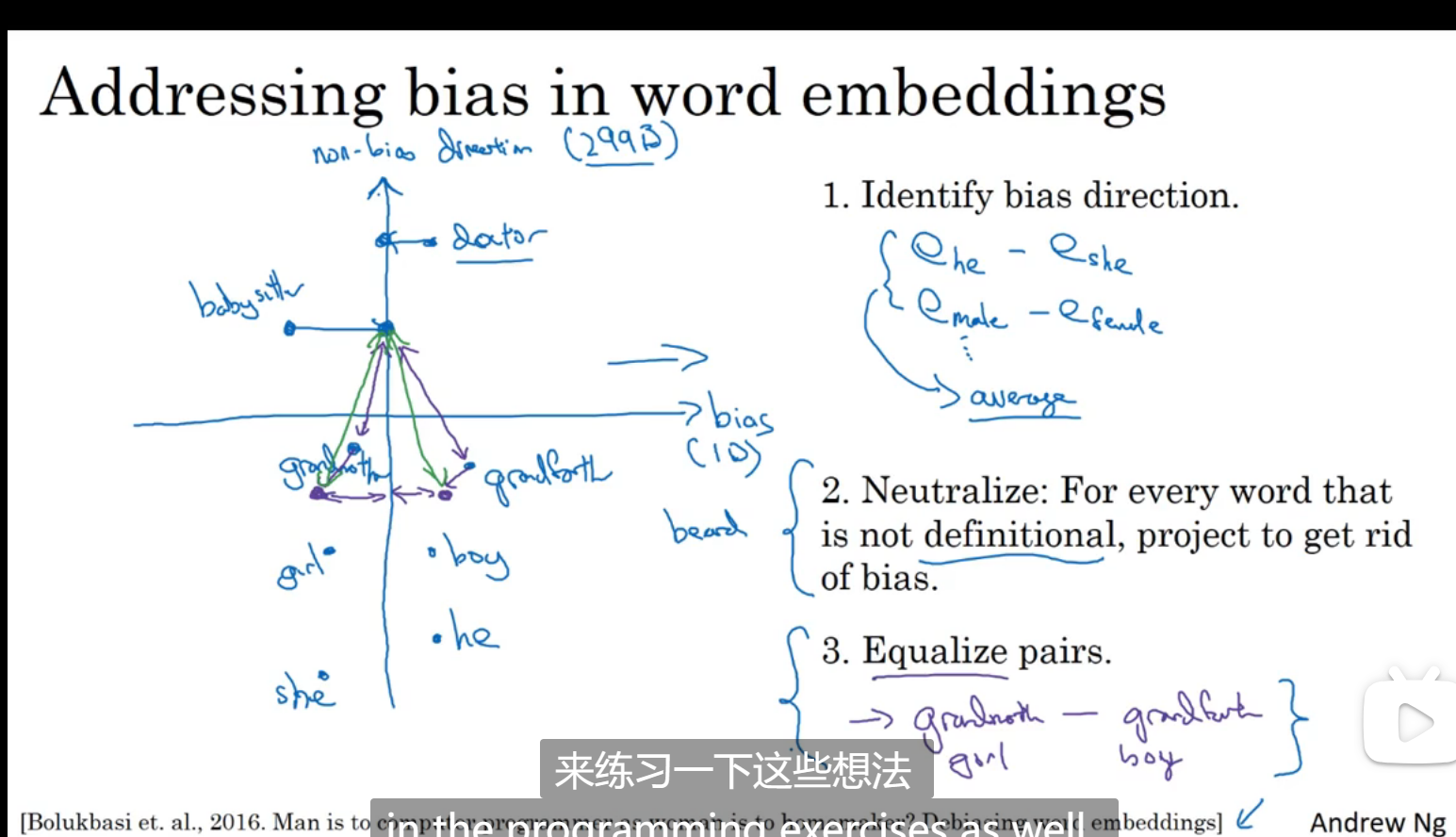
词嵌入除偏
存在偏见,如下图,下图是一个训练好的语言模型得到的结果

第一步:判断出我们要减少什么偏见
第二步:对本来不应该有偏见的词,即中立的词出现偏见之后将他们往中和值靠近
第三步:把本身对立的,比如祖母和祖父移到靠近中和值差不多位置的地方
深度学习week5_2
install_url to use ShareThis. Please set it in _config.yml.


