深度学习week5_3
版权申明:本文为原创文章,转载请注明原文出处
深度学习week5_3
基础模型
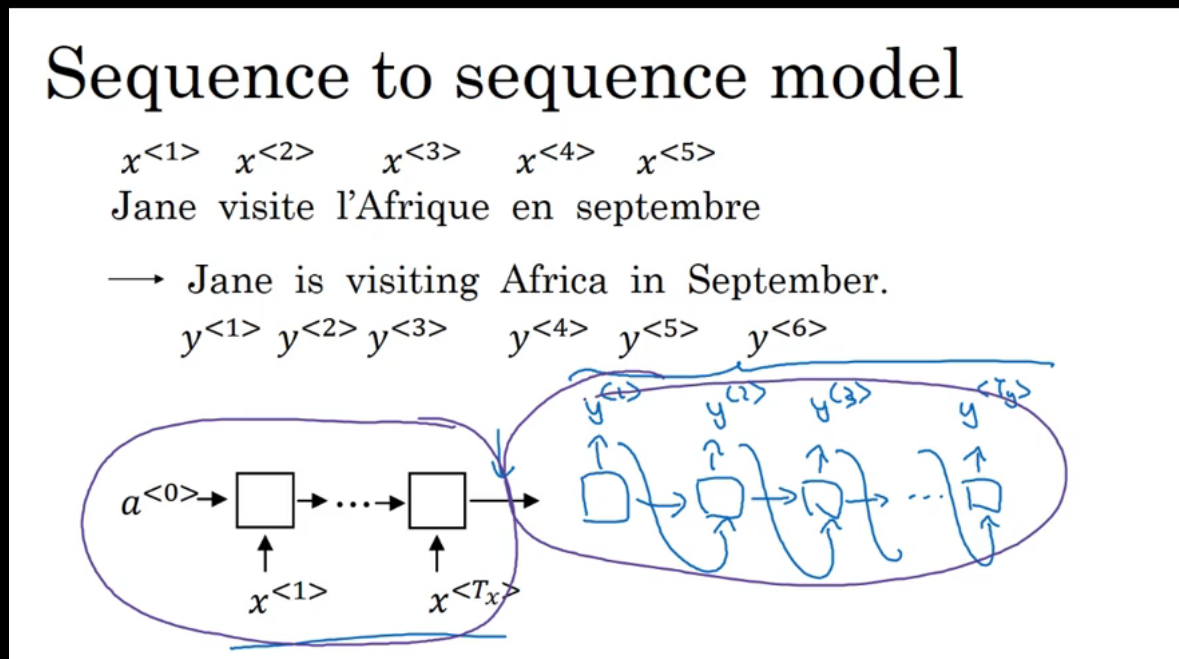
翻译模型(seq2seq):
- 建立一个编码网络,对输入进行编码,也就是进行学习
- 建立一个解码网络,当所有的输入完了之后对编码后的变量进行解码得到翻译的结果
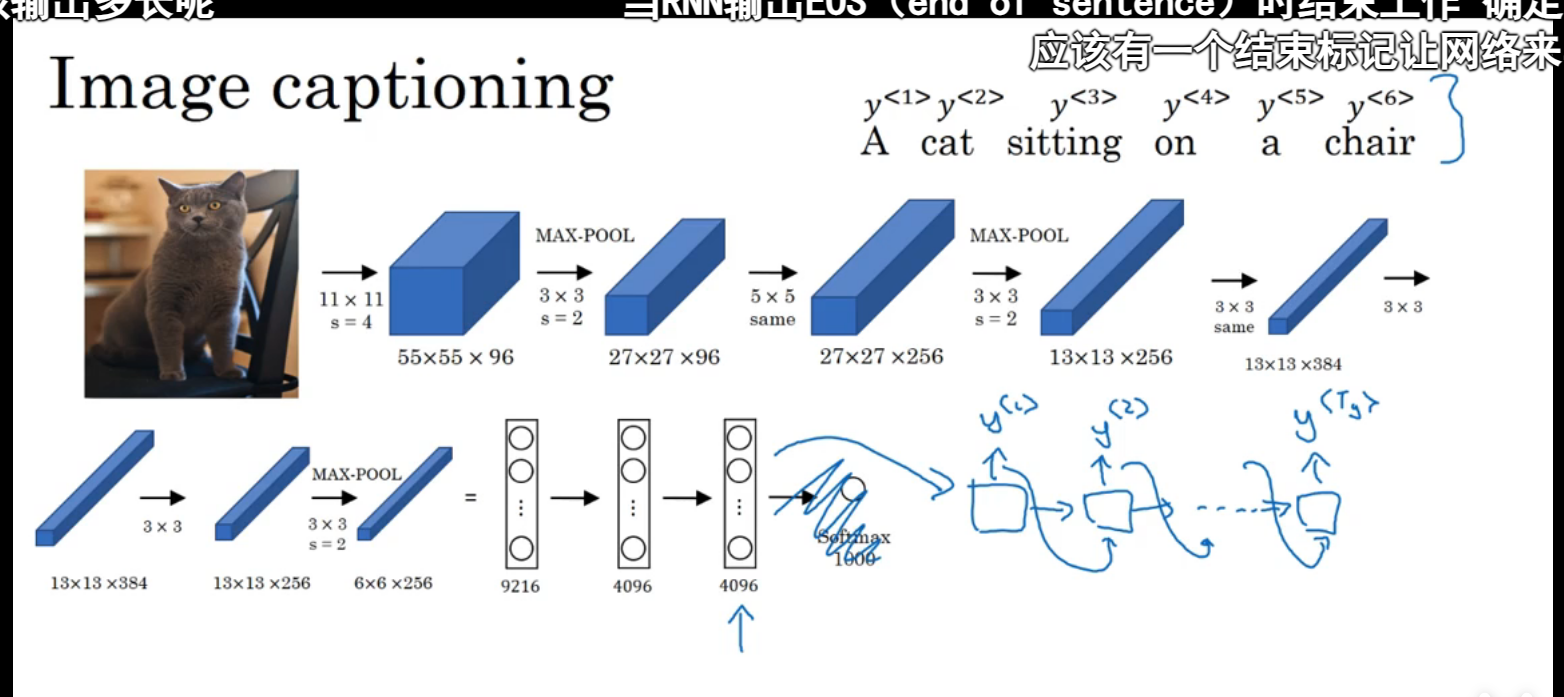
类似的还有通过一张图片得到输出(img2seq),比如通过如下图片得到这只猫坐在沙发上的句子:
选择最可能的句子
机器翻译vs语言模型,有很多类似的地方,机器翻译也叫做局限性的语言模型
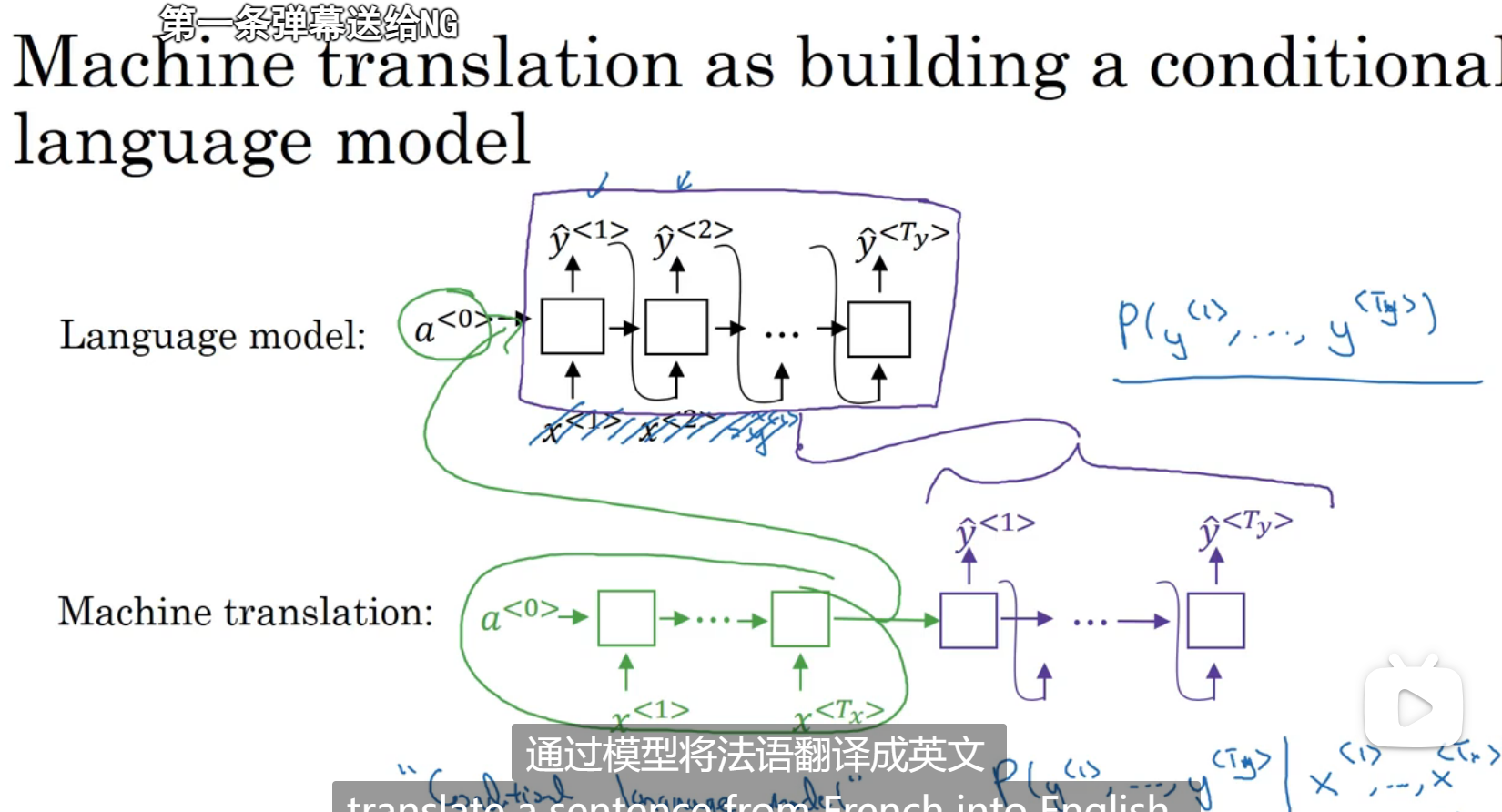
但是生成的y的质量要确保最好,使得最好的那项最大化
可能的结果:

为什么不选择贪心算法,贪心算法是一个一个的选单词出来,先选最有可能的y1,再在这个基础上选最有可能的y2,但是可能就会导致初夏下图第二排的结果,因为going比visiting更常见,但是我们不希望这种:

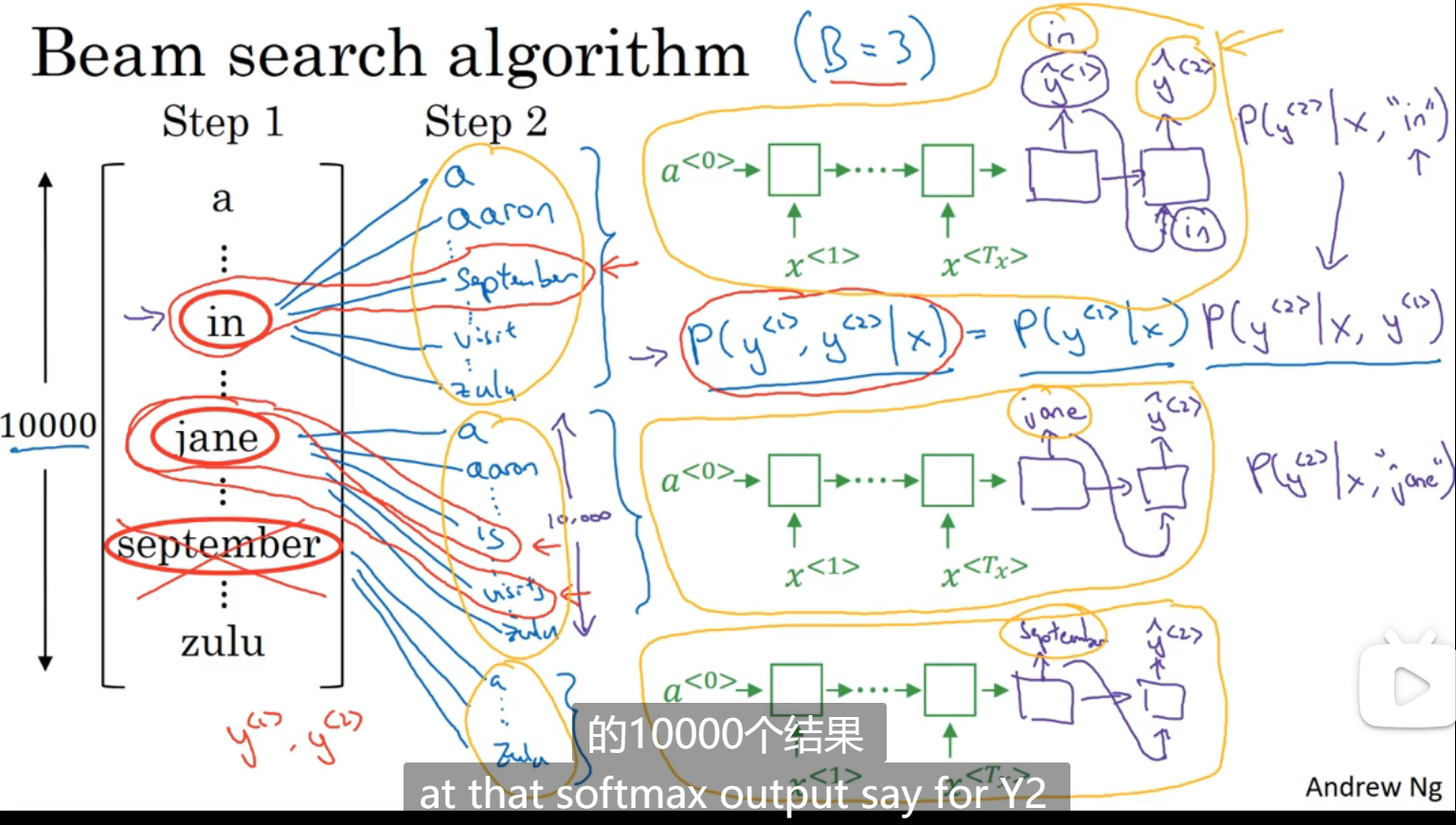
定向搜索
也叫做集束搜索
集束搜索会考虑多个选择,贪心算法只会选择最有概率的那个 B:集束宽,表示一次考虑B个选择,比如step1,就从所有词表中选出三个最有可能的选择,然后分别对这三个选择再算其所有词表的概率,从30000个里面选出最优的三个选择
改进定向搜索
长度归一化(如果不归一化最后得到的概率一定是一个很小的数字,因为有很多个小于1的数字相乘,两种方法,直接log或者再除于这段语句的长度):

怎么选择B(束):

定向搜索的误差分析
出现错误的翻译(比较输出错误的概率和正确的概率):

如果算法得到的单词比人类的单词概率更高,说明是RNN模型有问题(尝试正则化或者增加样本),如果更低,就是束搜索有问题,选择了错误的y(尝试更大的B)

Bleu得分
评估模型
给定一个机器生成的翻译,它能够自动的计算一个分数来衡量机器的好坏
衡量的一个指标是精确度,就是机器翻译结果的每一个单词在参考中是否出现,第二个是机器翻译的结果在参考中出现最多的是多少个单词

比较二元词组(count是出现在输出里的次数,countclip是在参考中的最多的出现次数):

多元词组:

Coursera官网提示: 这里的otherwise应该是exp(1-reference_output_length/MT_output_length)
这里是得分,如果MT翻译短了得分需要降低,所以幂需要变小,减掉的项应该变大,所以应该是reference/MT

注意力模型直观理解
如果机器每次都要先记忆整个句子输入完了之后在翻译,有可能这个句子非常的长,这将导致记忆很困难,最后的输出就像蓝色的线,对于短句子效果好,对于长句子效果不好

注意力模型实现绿色的线
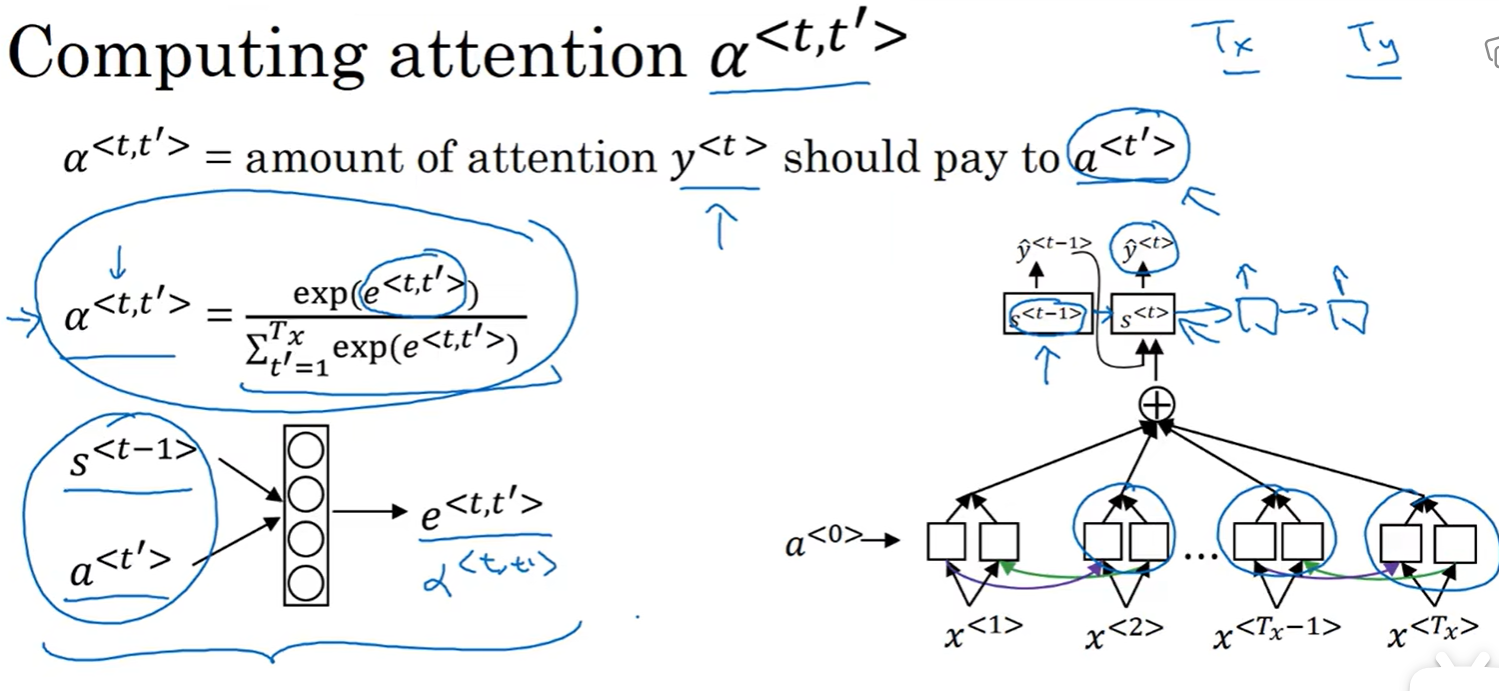
在正常双向RNN计算出输出之后,再有一层隐藏单元,这里的α<1,1>表示注意力,表示第一个输出的再第一个输入的输出这里的注意值是多少,以此类推
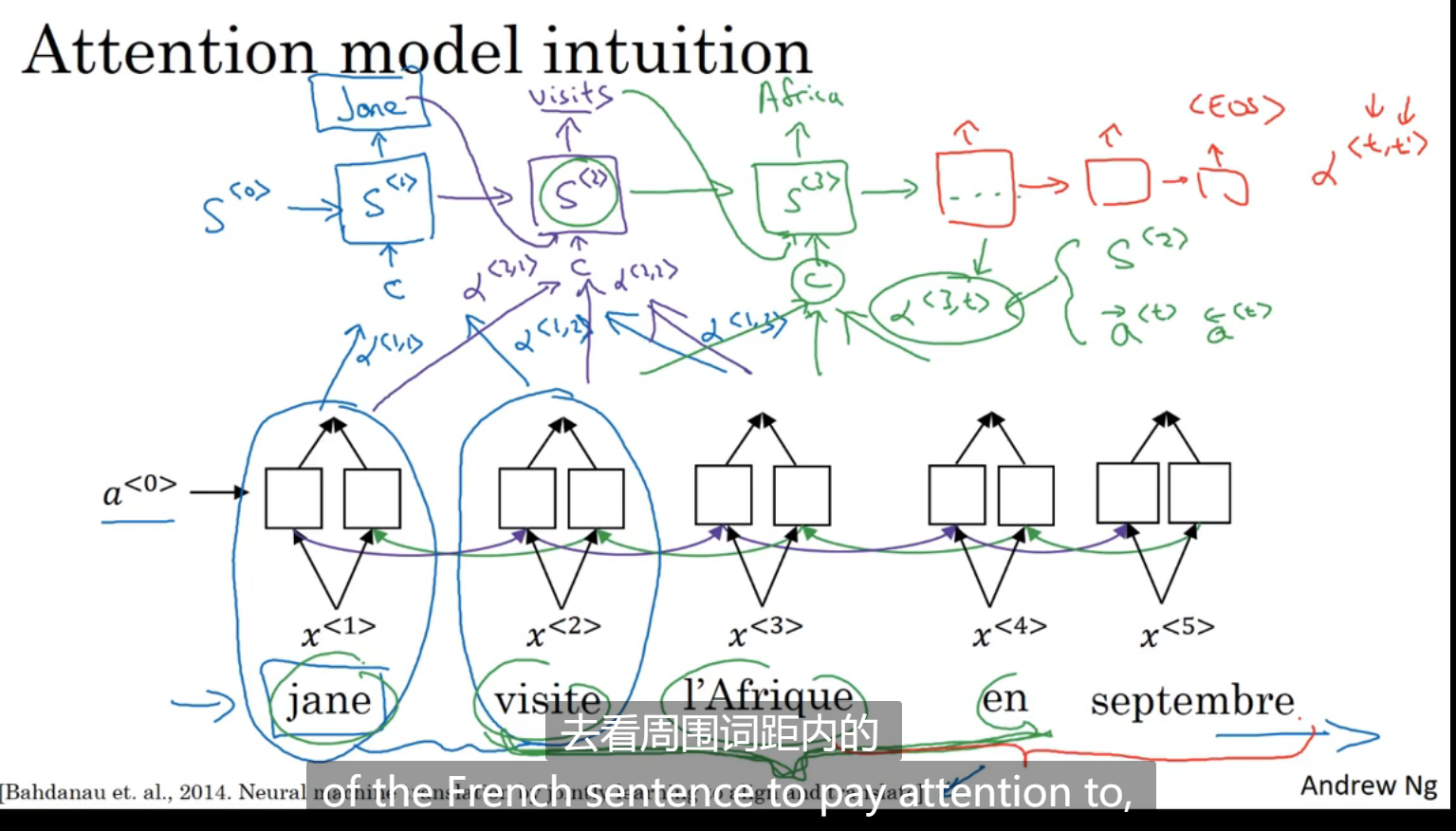
注意力模型
对于一个输出,所有的注意力权重之和为1,如图所示c<1> c<2>是算出来的输入到隐藏层的值
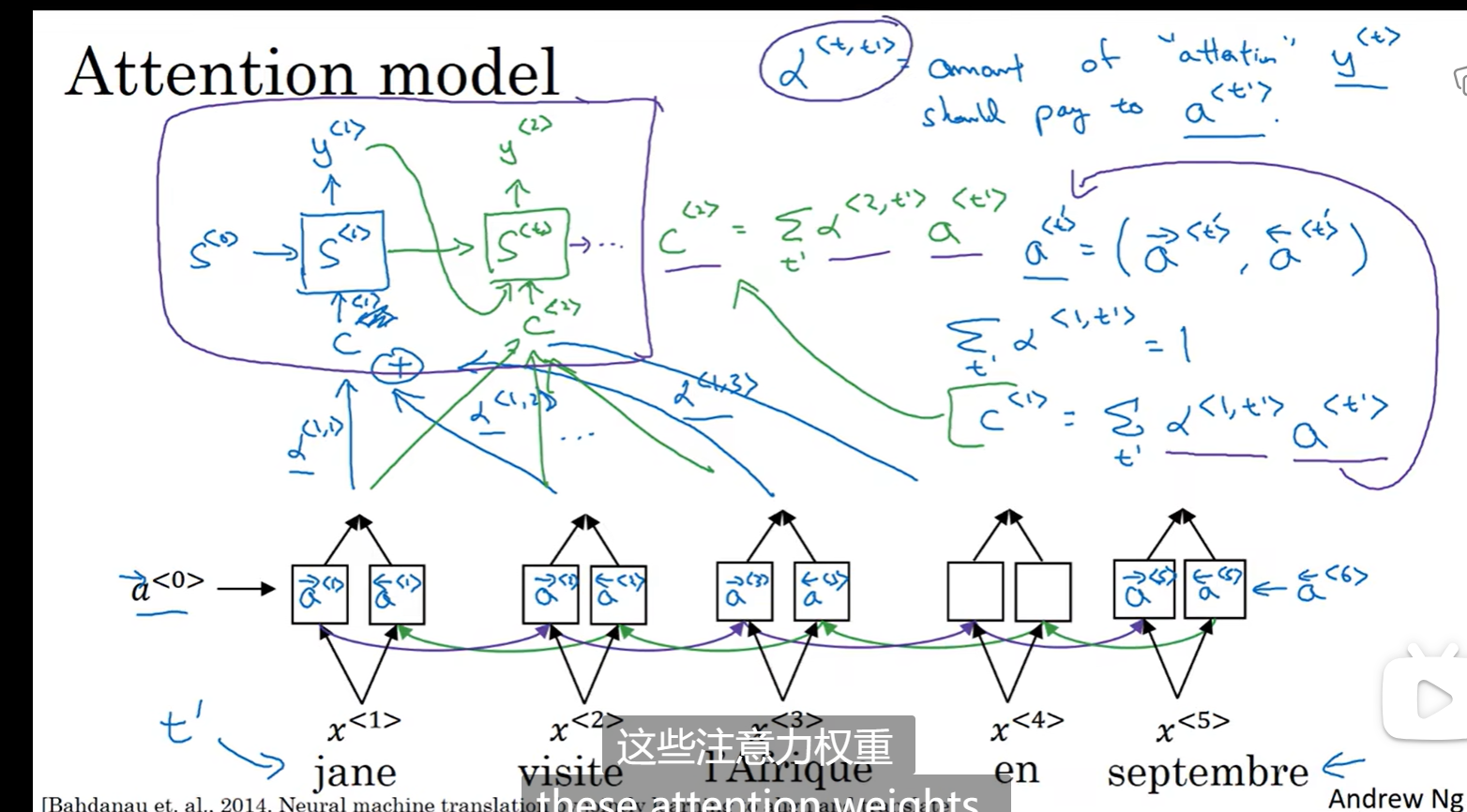
如图所示a<t,t_hat>是和S
语音辨识
将音频自动生成文字
音频数据的常见预处理步骤:就是运行这个原始的音频片段,然后生成一个声谱图,横轴是时间,纵轴是频率,图中的颜色代表了声音的能量,还有伪空白输出,也就是在音频被输入到学习算法之前,而人耳所做的计算
过去科学家们认为用一些基本的音位单元来表示音频是做语音识别最好的方式,现在已经不需要了
注意力模型的语音辨识:
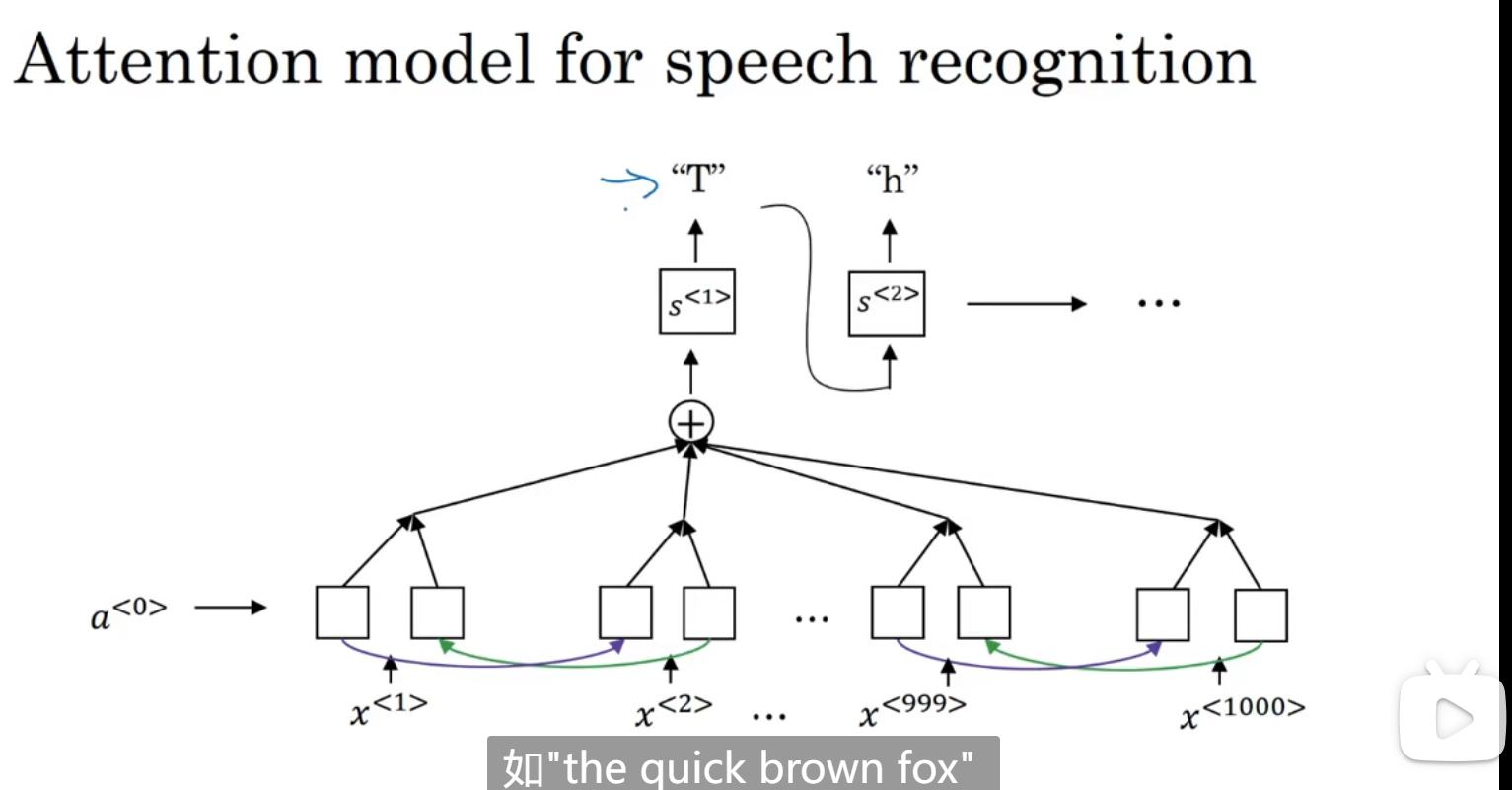
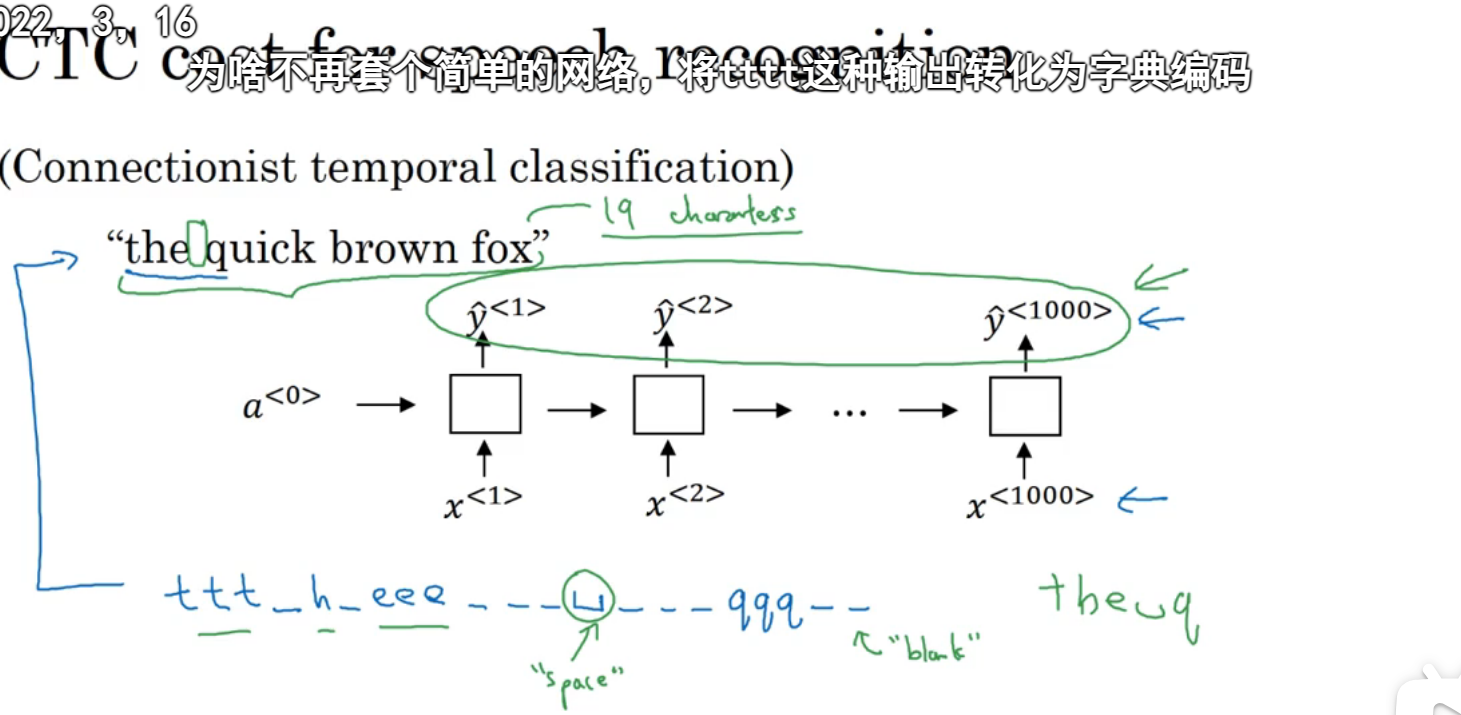
还有种方法:CTC损失函数,语音识别通常输入维度大于输出维度,因为语音识别的话输入是赫兹,可能包含很多个样本,那对于一个输入对应一个输出的结构怎么办呢:用特殊字符代表空白字符,这里用下划线表示空白字符:
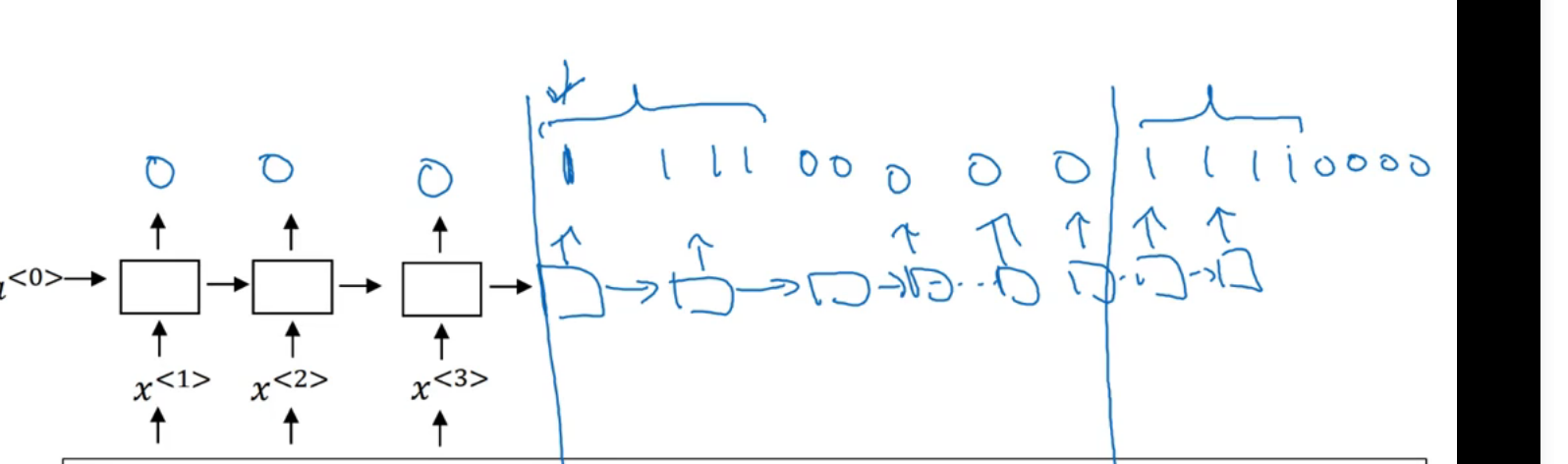
触发字检测
所谓触发字检测就是,语音说敏感词汇:比如 嘿siri
在接收到敏感词汇时输出1
深度学习week5_3
install_url to use ShareThis. Please set it in _config.yml.


