
leetcode100题_1
版权申明:本文为原创文章,转载请注明原文出处
leetcode100题_1
这里是leetcode必做100题,包含了我自己想到的思路以及看了题解之后理解的思路,(ps:前面几个太懒了没写知识点,后面都有写哦!QwQ)
2023.8.3:突然发现随机一题里面不是必做100题题库里的(TwT),没事,多多益善吧OvO
2023.8.7:本来想写到一起的,但是感觉太多了,另起新篇章吧
两数之和(简单题)
题目描述
给定一个整数数组 nums 和一个整数目标值
target,在该数组中找出 和为目标值
target 的那 两个
整数,并返回它们的数组下标。
输入:nums = [2,7,11,15], target = 9
输出:[0,1] 因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
题解
暴力求解
(ps:看到这种题自己的第一反应还是暴力求解/(ㄒoㄒ)/~~,复杂度直接上升到o(n^2),下面就不介绍暴力求解思路了,直接附上代码,大概需要注意的就是returnSize需要修改)
1 | int* twoSum(int* nums, int numsSize, int target, int* returnSize){ |
构造哈希
思路
暴力求解是先遍历i,再遍历j,使得两个数之后为target,但这种方法就需要对每一个i遍历一遍数组,那就想办法遍历i之后直接找到j的值,也就是通过nums[j]=target-nums[i]从而得到nums[j]的值,根据nums[j]的值,直接确定j下标,哈希表可以做到这件事,总体思路就是把nums[i]当成键存在哈希表中,值为原键值,target-nums[i]的值不在索引中里,就进行添加,这样只需要遍历一次
代码
1 | class Solution { |
关键部分解释
auto用于自动推断x变量的类型,因为其类型比较复杂且比较长,使用auto可以简化代码,使代码更加简洁易读。x->second是哈希表迭代器x指向的元素的值部分,键部分是通过x->first来获取的,在这里两个相同
字母异位词分组(中等题)
题目描述
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"] 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
思路
又是一个哈希题,该题我们主要要解决的找到字母异味词,并排列在一起,我们可以找到一种字母异味词的共同点,还是用哈希的方法,哈希的键为这个共同点,哈希的值为具体的字符串,这个共同点官方给出了两种,下面只提供一种方法,还看到一种题解将每个字母设为一个质数,一个字符串就用所有字母对应质数的乘积表示,也可以确定不同的字母异味词有不同的结果
以字母排序后的结果为共同点
代码如下:
1 | class Solution { |
有效的括号(简单题)
题目描述
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个右括号都有一个对应的相同类型的左括号。
题解
思路
思路并不复杂,很简单的堆栈结构,先进先出,遍历一遍字符串,如果是),},]就插入堆,如果是{,(,[就和堆最后一个字符比较,如果匹配成功堆就取出这个数据
代码:
1 | class Solution { |
判断单词是否能放进填字游戏内(中等)
题目描述
给你一个 m x n 的矩阵 board ,它代表一个填字游戏 当前 的状态。填字游戏格子中包含小写英文字母(已填入的单词),表示 空 格的 ' ' 和表示 障碍 格子的 '#' 。
如果满足以下条件,那么我们可以 水平 (从左到右 或者 从右到左)或 竖直 (从上到下 或者 从下到上)填入一个单词:
该单词不占据任何 '#' 对应的格子。 每个字母对应的格子要么是 ' ' (空格)要么与 board 中已有字母 匹配 。 如果单词是 水平 放置的,那么该单词左边和右边 相邻 格子不能为 ' ' 或小写英文字母。 如果单词是 竖直 放置的,那么该单词上边和下边 相邻 格子不能为 ' ' 或小写英文字母。 给你一个字符串 word ,如果 word 可以被放入 board 中,请你返回 true ,否则请返回 false 。
eg: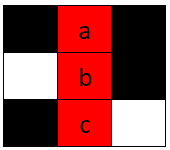
输入:board = [["#", " ", "#"], [" ", " ", "#"], ["#", "c", " "]], word = "abc" 输出:true 解释:单词 "abc" 可以如上图放置(从上往下)。
题解
思路
由于可以正向匹配和反向匹配,所以我直接用两次匹配,一次正向,一次反向
由于可以行匹配和列匹配,所以用了两个for循环,两个循环结束之后对word进行逆转,反向匹配
每次匹配到空格或者第一个字符的时候就删掉word第一个字符,中间过程但凡有一个不合规范,比如遇到了不属于该字符串的字符立马恢复word(用word2存储原始的word,逆转的时候注意逆转word2)
以word的长度为0作为判断条件,但是需要确保向下邻近或者向有邻近的字符是#或者没有
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76class Solution {
public:
bool placeWordInCrossword(vector<vector<char>>& board, string word) {
int x=board.size();//行数
int y=board[0].size();//列数
string word2=word;//为了恢复
char firstChar = word[0];
for(int i=0;i<2;i++){
for(int xx=0;xx<x;xx++){//对每一行
for(int yy=0;yy<y;yy++){//对每一行的每个位置
if((y-yy)>=word.length()&&board[xx][yy]!='#'){
if(board[xx][yy]!=firstChar&&board[xx][yy]!=' '){
word=word2;
firstChar = word[0];
while((y-yy)>=word.length()&&yy<y-1&&board[xx][yy+1]!='#'){
yy++;
}
}else{
word.erase(0, 1);//erase 函数的第一个参数表示要删除的起始位置,第二个参数表示要删除的字符数量。
if(word.length()==0){
if(yy<y-1&&board[xx][yy+1]!='#'){
word=word2;
while((y-yy)>=word.length()&&yy<y-1&&board[xx][yy+1]!='#'){
yy++;
}
}else{
return true;
}
}
firstChar = word[0];
}
}else{
word=word2;
firstChar = word[0];
}
}
}
word=word2;
firstChar = word[0];
for(int yy=0;yy<y;yy++){//对每一列
for(int xx=0;xx<x;xx++){//对每一行的每个位置
if((x-xx)>=word.length()&&board[xx][yy]!='#'){
if(board[xx][yy]!=firstChar&&board[xx][yy]!=' '){
word=word2;
firstChar = word[0];
while(xx<x-1&&board[xx+1][yy]!='#'){
xx++;
}
}else{
word.erase(0, 1);//erase 函数的第一个参数表示要删除的起始位置,第二个参数表示要删除的字符数量。
if(word.length()==0){
if(xx<x-1&&board[xx+1][yy]!='#'){
word=word2;
while(xx<x-1&&board[xx+1][yy]!='#'){
xx++;
}
}else{
return true;
}
}
firstChar = word[0];
}
}else{
word=word2;
firstChar = word[0];
}
}
}
reverse(word2.begin(),word2.end());
word=word2;
firstChar = word[0];
}
return false;
}
};
跳跃游戏(中等)
题目描述
给定一个长度为 n 的 0 索引整数数组
nums。初始位置为 nums[0]。每个元素
nums[i] 表示从索引 i
向前跳转的最大长度。换句话说,如果你在 nums[i]
处,你可以跳转到任意 nums[i + j]
处:0 <= j <= nums[i]
i + j < n
返回到达 nums[n - 1]
的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]
题解
预备知识
vector<int> a(2);是一个单独的vector对象,初始化大小为2。vector<int> a[2];是一个长度为2的数组,数组中的每个元素都是一个独立的vector对象。(相当于定义两个数组)
思路
思路一:
先来讲一下lz自己的思路吧/(ㄒoㄒ)/~~(比较麻烦,但是确实做了好久)
同时进行一跳,比如在索引0位置时,索引0位置的值是3,那就同时进行0、1、2、3跳,然后存下这三跳的位置,再从这三跳再同时往下跳,期间为了减少缓存和运行时间,将每一跳到的位置存下来,如果之后有某一条跳到了该位置自动忽略,也就是每个点只跳一次
代码:
1 | class Solution { |
思路二:
看了一下好像和lz的思路一致,只不过不用对要跳的格子数进行遍历,只记录一个范围(好像确实快很多!)
1 | int jump(vector<int> &nums) |
罗马数字转整数(简单)
题目描述
罗马数字包含以下七种字符: I, V,
X, L,C,D 和
M。
1 | 字符 数值 |
例如, 罗马数字 2 写做 II ,即为两个并列的
1 。12 写做 XII ,即为 X +
II 。 27 写做 XXVII, 即为
XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4
不写做 IIII,而是 IV。数字 1 在数字 5
的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9
表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
题解
思路
思路很简单,就是一个一个的比,比到I C X就注意一下
(看到一种更简单的,直接将对应值存在字典里,有两个字符的也一样)
代码
1 | class Solution { |
不同路径(中等)
题目描述
一个机器人位于一个 m x n 网格的左上角
(起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
思路
思路一:
深度优先,这是lz自己想到的方法但是会超时呜呜呜/(ㄒoㄒ)/~~
思路二:
数学函数排列组合,向右向下的路径长度是知道的,用排列组合,假如到达终点需要向下三格向右六格,最大路径长度就相当于从九个需要的动作里选出两个(不要求顺序),但是由于lz用的c++,该方法会数值会超过限定
思路三
动态规划:到达每一格的最大路径数量其实就是它的左边那一格和上面那一格的最大路径数量之和
我们只需要初始化边上的最大路径长度数量,由于在边缘,最大路径数量肯定是1
1 | class Solution { |
两个数组的交集(简单)
给定两个数组 nums1 和 nums2 ,返回
它们的交集 。输出结果中的每个元素一定是 唯一
的。我们可以 不考虑输出结果的顺序 。
思路:简单遍历查找
首先对nums1去重,再对nums1的每个元素遍历,用find查找nums2是否有对应项
代码
1 | class Solution { |
反转链表(简单)
知识点
普通结构体使用,可以用 . 当是用指针指向结构体时,使用->。
eg: (*node).data的作用等于node->data
它们都是访问node指针所指向的结构体的data成员。*node是node这个地址里存的值,也就是一个结构体对象,所以你可以用点运算符来访问它的成员。而node是这个结构体的地址,所以你可以用箭头运算符来访问它所指向的对象的成员。箭头运算符是一种方便的写法,相当于先对指针进行解引用,然后再用点运算符。
思路
就是很简单的一个循环
pos为当前位置,s指向pos前面一个,q指向pos的next,每次循环的时候让pos->=s;s=pos;pos=q如果这个时候pos为NULL了说明全部数据已经反制了,return s;如果还没有,继续让q=pos->next;
代码
1 | /** |
把字符串转换为整数(中等)
题目描述
写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
知识点
1、C++字符数字怎么转换为整数型数字
1 | char s='2'; |
2、C++没有求幂的运算符,
c++头文件加 #include<math.h> 使用pow(x,y),可算出x的y次幂
思路
首先获取去除前面的空格,然后比较第一个字符是否为正负号或者在0到九之间,不在就返回零,接着如果有正负号就记录下来,再去除前面的0,将每一个字符转换为数字存在num数组里,如果发现了不为数字的直接跳出循环,我这里就直接让i=length了,接着判断num的长度,大于10直接判定超出了范围,但是等于10的也可能超出范围了,就用longlong定义sum,可以保存更大的值以判断超出范围
1 | class Solution { |
替换空格(简单)
知识点
1, vector转换为string
1 | vector<char> vec { 'A', 'B', 'C' }; |
2, char转换为str
1 | char s='1'; |
思路
用vector代替string(主要是因为我直接的vector在末尾插入元素的操作QwQ)
后面找到了:
C++ string类有多种在末尾插入字符的函数,其中一种是append函数。这个函数有多个重载版本,可以接受不同类型的参数,比如字符串,字符数组,字符,迭代器等。可以这样使用append函数:
1 | std::string str = "Hello"; |
代码
1 | class Solution { |
子集(中等)
题目描述
给你一个整数数组 nums ,数组中的元素
互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
1 | 输入:nums = [1,2,3] |
知识点
什么是动态规划:
动态规划就是把复杂的问题分解为简单的子问题的求解方式。
动态规划的基本思路:通常用于求解具有某种最优性质的问题,试图只解决每个问题一次一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个子问题解之时直接查表。动态规划自底向上(迭代而非递归)求解问题,避免重复计算。
而对于递归,求解这些子问题,然后合并子问题的解得到原问题的解。区别在于这些子问题会有重叠,一个子问题在求解后,可能会再次求解。
所以,我们可以将这些子问题的解存储起来,不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。下次使用时,直接把结果拿来用即可。这就是动态规划法的基本思路。
思路
ps:这道题感觉是近期做过最舒适的一题了,我采用的是动态规划方法(看了别人的题解才知道自己的方法原来是动态规划QwQ)
我们可以很容易发现一个规律,其实最后的子集求法可以一个一个元素算,比如最开始是空集,在遇到第一个元素1时,在空集的基础上加上1得到1数组,存储空集和1数组,在遇到2时分别在空集和1数组基础上加2,并存在最后的数组的集合中去,以此类推
代码
1 | class Solution { |
最长连续序列(中等)
给定一个未排序的整数数组 nums
,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
知识点
对数组进行排序:
1
2vector<int> vec(10);
sort(vec.begin(),vec.end());去重
1
vec.erase(unique(vec.begin(), vec.end()), vec.end());
思路(两种思路)
偷了个懒,直接去重排序了,等lz有空了就用哈希
2023.09.18:欠的债总是要还的
代码
1 | class Solution { |
思路二:哈希
用哈希存储以每个数字为结尾的有序并连续数组的最大长度,首先都初始化为0,然后从头开始遍历,比如遍历的数字是nums[i],就找nums[i]-1是否存在,如果存在再确定前一个是否存在,找到最前一位,然后将那个值的哈希设为1,依次加一,下次遍历的时候只需要判断是否哈希为0,如果是就说明还没有进行确定最长连续数组,如果不为0就不需要重复运算,lz估测时间复杂度应该为n,因为实际上只是循环了两个数组,第一次遍历,第二次确定每个数字以自己为结尾的最长有序连续数组,不会重复运算
代码二:
1 | class Solution { |
最长回文子串(中等)
题目描述
给你一个字符串 s,找到 s
中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
知识点
vector删除指定元素
1
hashmap[i+1].erase(hashmap[i+1].begin() + index);
string复制部分内容
1
2string s="abcdef";
string d(begin(s)+2,begin(s)+5);
思路
动态规划
首先给每个键值定义一个数组,该数组将存储该列表所有下标对应的可和右边的组成回文子串的下标,也就是比如下标一可以和下标二组成回文,就存上hash[1]={1,2},初始化每个元素都可以自己组成回文列表
- 初始化一个二维vector,对应着该下标与某下标可形成回文串,比如vec[1]={1,2,3,4}代表着1位置的该字符可以形成回文子串,1-2两个元素组成的子串可以形成回文,1-3形成的子串可以形成回文
- 从右往左遍历元素,对于遍历的每个元素判断是否和左边挨着的那个元素相等(因为等会遍历不到),如果相等,就存在vector中
- 接下来遍历左边挨着的那个元素对应可形回文的下标,判断和那个下标右边的值是否相等
- 最后遍历所有下标对应的数组,找到最大值,并返回字符串
代码
1 | class Solution { |
二叉树的最大深度(简单)
题目描述
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
思路
用递归,很简单的思路,也有点动态规划那意思,就是从根节点开始计算,一直向下延申,直到有NULL出现,如果已经是叶子节点就从该处开始向上加就是该叶子结点的深度,用max找出最大的
代码
1 | /** |
K个一组翻转链表(困难)
ps:没错这是一个困难题,但是lz一次就做对了啊啊啊啊好激动好开心o( ̄▽ ̄)ブ
题目描述
给你链表的头节点 head ,每 k
个节点一组进行翻转,请你返回修改后的链表。
k
是一个正整数,它的值小于或等于链表的长度。如果节点总数不是
k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
思路
我最开始的很麻烦的想法是将连续k个隔离出来,然后进行逆转拼接,文字不太好描述,以下图像比较好理解

但是这样就很麻烦,因为我需要记录要逆转的前一个节点,最后一个节点挨着的那个节点,感觉思路没问题但是如果有细节没考虑到那就得调试很久,主要主程序会有很多个变量,这让lz很头痛
接着又开始思考,通过画图分析,我想到可以先对要逆转的那一部分全部进行逆转,再以k为单位进行逆转,这样的话整体对象都是一个链表,调试应该会好很多,重点只需要放在以k为单位逆转上,前面的全部逆转相当于k=1,重新写一个函数用来实现该功能,并返回起始节点和末节点方便进行拼接,大概思路如图所示

接下来介绍一下以k为单位逆转的思路

代码
1 | /** |
括号生成(中等)
因为赶时间没有细想,看了题解
题目描述
数字 n
代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且
有效的 括号组合。
知识点
vector复制
1
2vector<int> vec;
vec.assign(array.begin(),array.end());//清空原数据,赋予新数据vector清空
1
vec.swap(vector<int>())
思路
我先说说自己最开始的思路吧,也是基于动态规划,就先生成一对括号(),然后i没加一()就再加一对括号,但是我加的方法有问题,我只考虑在旁边加一个(),整体加一个括号,也就是
1 | str1="()"+str; |
但是这样会有问题,如果n=4,那么没办法生成(())(())因为一次要么在旁边加要么整体加
看了题解发现了一种更巧妙加括号的方式,还是一样的思路,在原来的基础上加括号,但是不一样的是这次就定了我加的括号的位置,然后往中间填充,因为我们确定第一个字符一定是(,那么只需要确定的)的位置,所以随后的字符串应该是如下拼接:
1 | str="("+p+")"+q; |
那么我们就需要确定p和q,这个只需要对p和q进行遍历,因为我们知道p+q总共需要多少个括号,然后根据该方法从小到大找出字符集
代码
1 | class Solution { |
组合总和(中等)
没做出来呜呜呜,感觉对深度优先还是不太熟练
题目描述
给你一个 无重复元素 的整数数组
candidates 和一个目标整数 target ,找出
candidates 中可以使数字和为目标数 target 的
所有 不同组合 ,并以列表形式返回。你可以按
任意顺序 返回这些组合。
candidates 中的 同一个 数字可以
无限制重复被选取
。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于
150 个。
示例:
1 | 输入:candidates = [2,3,6,7], target = 7 |
知识点
vector<vector<int>> combinationSum(vector<int>& candidates, int target)的&:&符号用于传递引用(reference)。在C++中,引用允许你通过引用参数修改函数外部传递给函数的变量,而不是传递变量的副本。- Deque
path = new ArrayDeque<>();:这行Java代码创建了一个双端队列(Deque),名为 path,其元素类型为整数(Integer)。在Java中,Deque是一种双向队列,可以从队列的前端或后端插入和删除元素,因此它具有栈和队列的功能。
思路
使用深度优先遍历的方法,总体思路在下图:

代码
1 | class Solution { |
移动零(简单)
题目描述
给定一个数组 nums,编写一个函数将所有 0
移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
知识点
c++的find会返回列表中该元素的第一个位置
交换两个数:使用c++自带的交换函数
1
swap(a,b);
思路
思路一
自己想到的解法过于粗糙了:
- 获取当前数组长度
- 删除所有为0的点
- 再次获取长度,获取前后长度差补零
代码一
1 | class Solution { |
思路二
准备两个指针:a,b a负责找不为0的值,一次加一,a找到不为0的值之后将值传给b,b+1,到最后当a找完了,b和a之间的值就换为0
代码二
1 | class Solution { |
接雨水(困难)
没做出来,好难呜呜呜
题目描述
给定 n 个非负整数表示每个宽度为 1
的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
思路
思路一:按行求
会超时
从最低下一层开始,开始遍历,找到高度大于层数的第一个点,然后记录后面跟着的连续的高度小于层数的个数,直到高度再次大于层数,这两者之间的差就是可以存的水
代码一
1 | class Solution { |
思路二:按列求
知识点
C++ Vector 最大 最小值 索引 位置
使用STL的Vector时,利用函数 max_element,min_element,distance可以获取Vector中最大、最小值的值和位置索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int main()
{
std::vector<double> v {1.0, 2.0, 3.0, 4.0, 5.0, 1.0, 2.0, 3.0, 4.0, 5.0};
std::vector<double>::iterator biggest = std::max_element(std::begin(v), std::end(v));
std::cout << "Max element is " << *biggest<< " at position " << std::distance(std::begin(v), biggest) << std::endl;
auto smallest = std::min_element(std::begin(v), std::end(v));
std::cout << "min element is " << *smallest<< " at position " << std::distance(std::begin(v), smallest) << std::endl;
}
输出:
Max element is 5 at position 4
min element is 1 at position 0</span>
思路
遍历数组,遍历位置为index,left记录遍历位置左边最大值索引,right记录遍历位置右边最大值索引,right在right<=index时更新,left在index处值大于left处值时更新,用maxelement+distance找到最大值索引
代码
1 | class Solution { |
思路三:动态规划
不用每次都求索引右边的最大值,这样时间复杂度会很大,用动态规划的方式求右边的最大值,也就是求出每个下标右边的最大值,从最右边开始算,和左边思路一致
代码三
1 | class Solution { |
思路四:双指针
从两个方向进行遍历,left是从左遍历的索引,right是从右遍历的索引,leftmax是left左边的最大值,rightmax是right右边的最大值,如果left左边的最大值比right右边的最大值还大的话,right处是可以储水的,因为就算right和left中间的值比right处的值小,但是在left左边的值比right大,就可以储水,但是left处不一定能储水,因为left处的值可能也比rightmax大,但是我们可以确保rightmax肯定大于等于right处的值,right就往左边移动,同时每一遍都分别比较right处值和left处值和rightmax,leftmax的大小,进行更新
代码四
1 | class Solution { |
leetcode100题_1
install_url to use ShareThis. Please set it in _config.yml.

