深度学习week4_3
版权申明:本文为原创文章,转载请注明原文出处
深度学习week4_3
目标定位
对象位置分类(classification with localization):在一张图中有一个较大的对象,对他进行识别并确认出位置
对象检测(detection):在一张图中有多个对象,对这多个位置对象进行检测识别并确认出位置
在输出中添加位置标签,bx by是物体中心点的坐标,宽bw,高bh,整张图片起始坐标为(0,0),终坐标为(1,1)
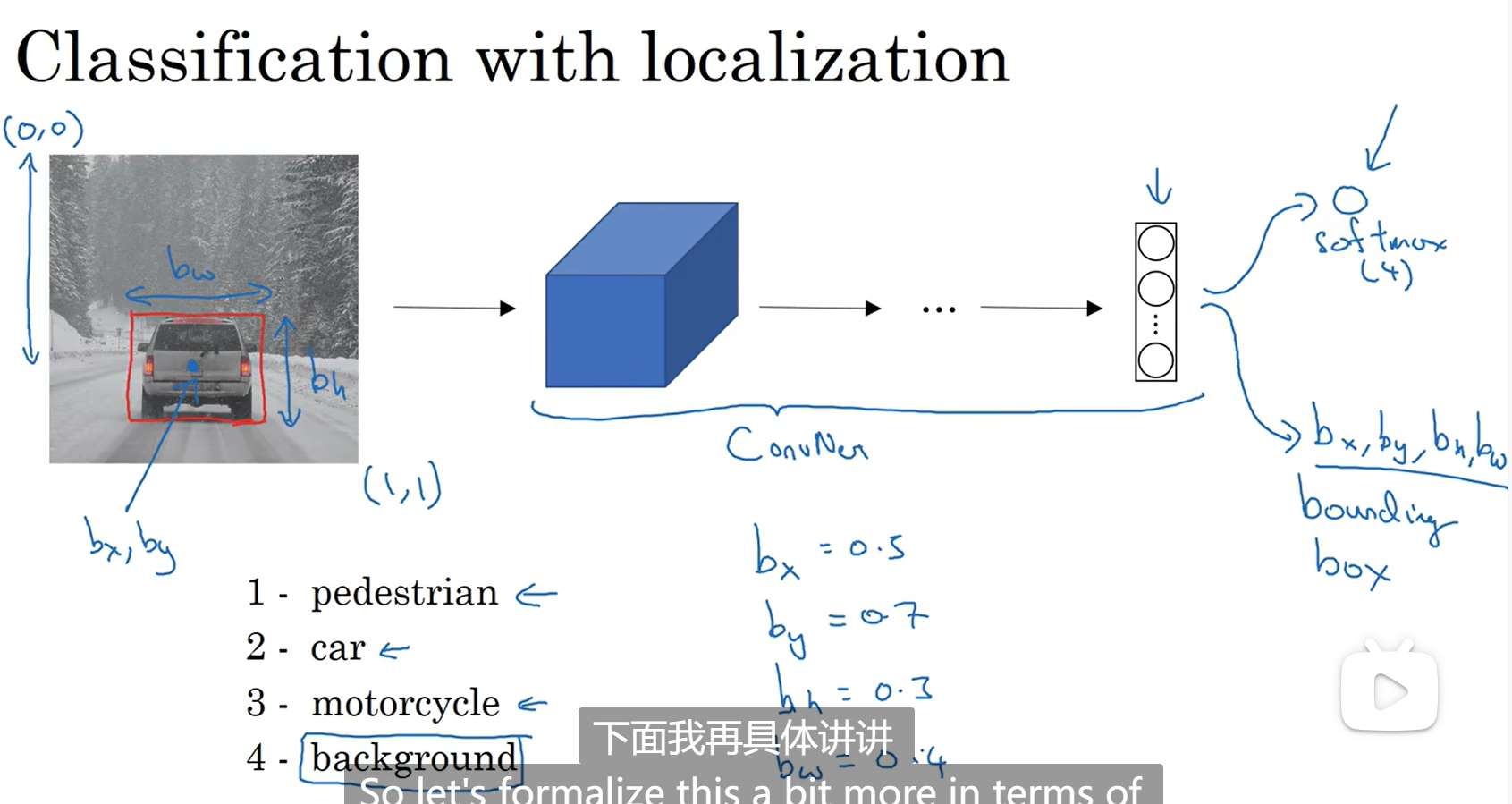
特征点检测
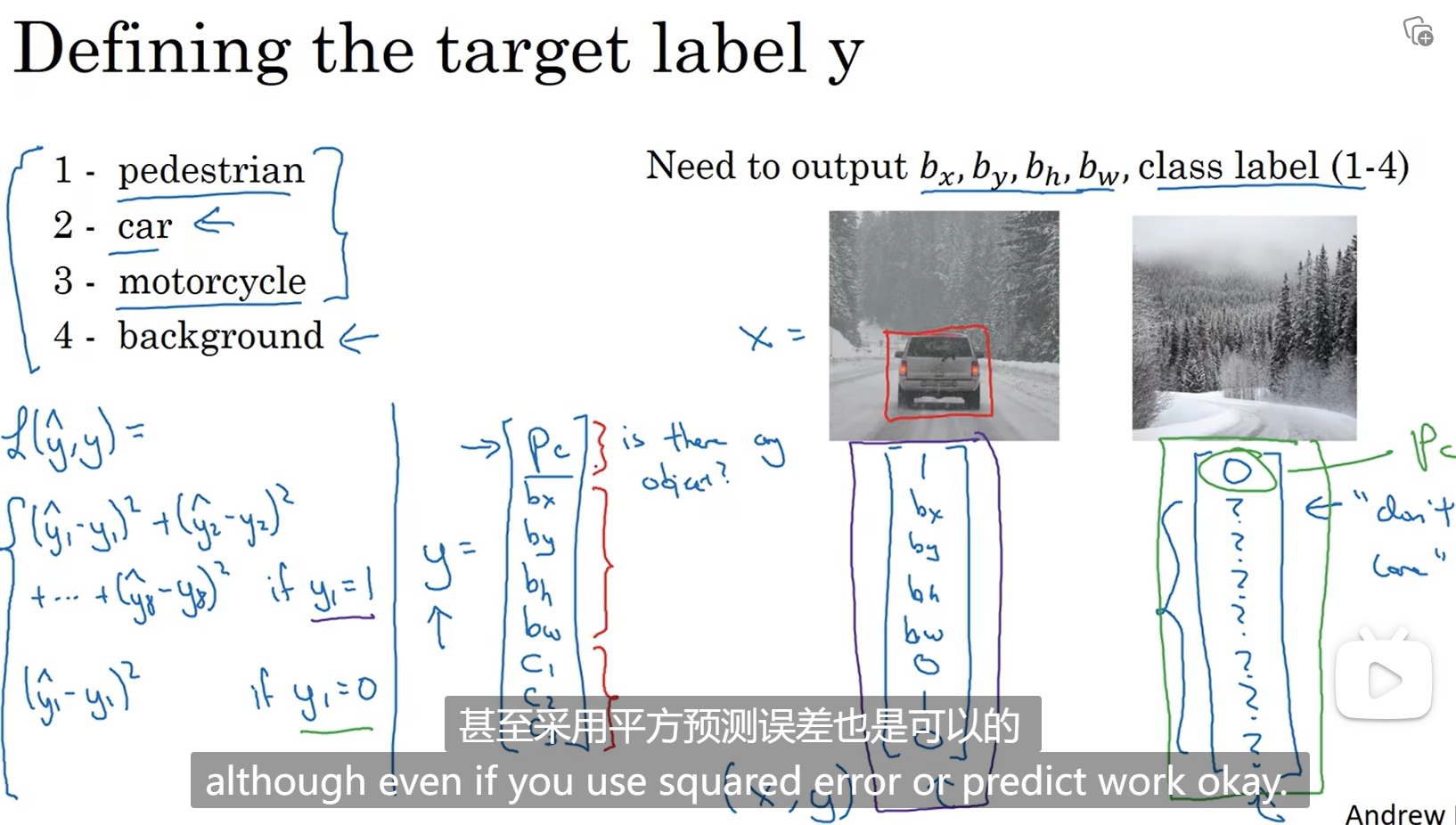
用pc表示该图中是否有对象,pc=0表示没有对象,那坐标,对象分类就没有意义了,loss函数只算pc和真实的y的值的误差;如果pc=1表示有对象,就需要算每个参数的误差
such as(如果要识别人脸的话,要确认眼角或者嘴角的具体坐标,先输出这张图是否包含人脸,如果包含再输出眼角或者嘴角的具体坐标,可能有很多,在下图中标记了64个嘴巴的坐标,更好学习,但是训练集需要手工标注,最后就需要了解用二维坐标确认人脸,同时确保所有标签在所有图片中处于同一位置,比如一个坐标是左眼角,那在所有的图片中该坐标都要表示左眼角):

目标检测
基于滑动窗口的目标检测
如图所示,采取不同大小的窗口,在一张图上做遍历,如果这个窗口所在位置检测到了对象,就输出1,窗口越大可能影响性能,窗口越小,成本函数代价大

卷积的滑动窗口实现
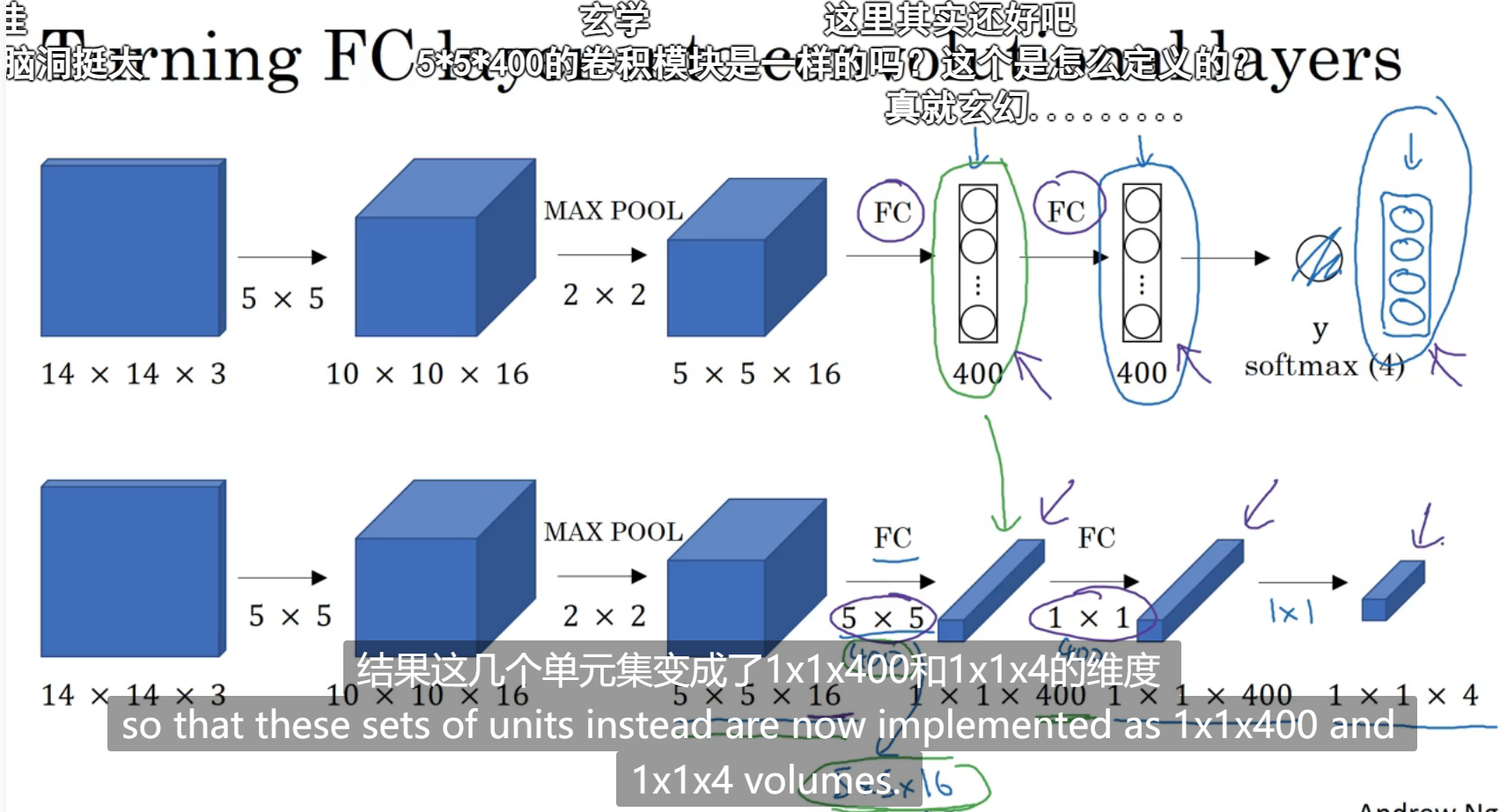
全连接层变成卷积层(如图所示,下面那一排全连接层的计算是用一个和输入维度一样的过滤器,过滤器的数量就是所有元素的数量,这里是400个,这样也能得到和全连接层一样维度的结果,但是神经网络更深):
事先训练好了14 14的训练集,然后新的样本是16 16的,我们应该用滑动窗口的方式,以14为一个,然后移动,但是这样重复的点会太多,我们发现直接在16上进行训练,最后得到的2 * 2矩阵就是我们用滑动窗口分别得到的结果,移动步长是2是因为,在最大池化那里的步长是2,在最下面那一排是一样的
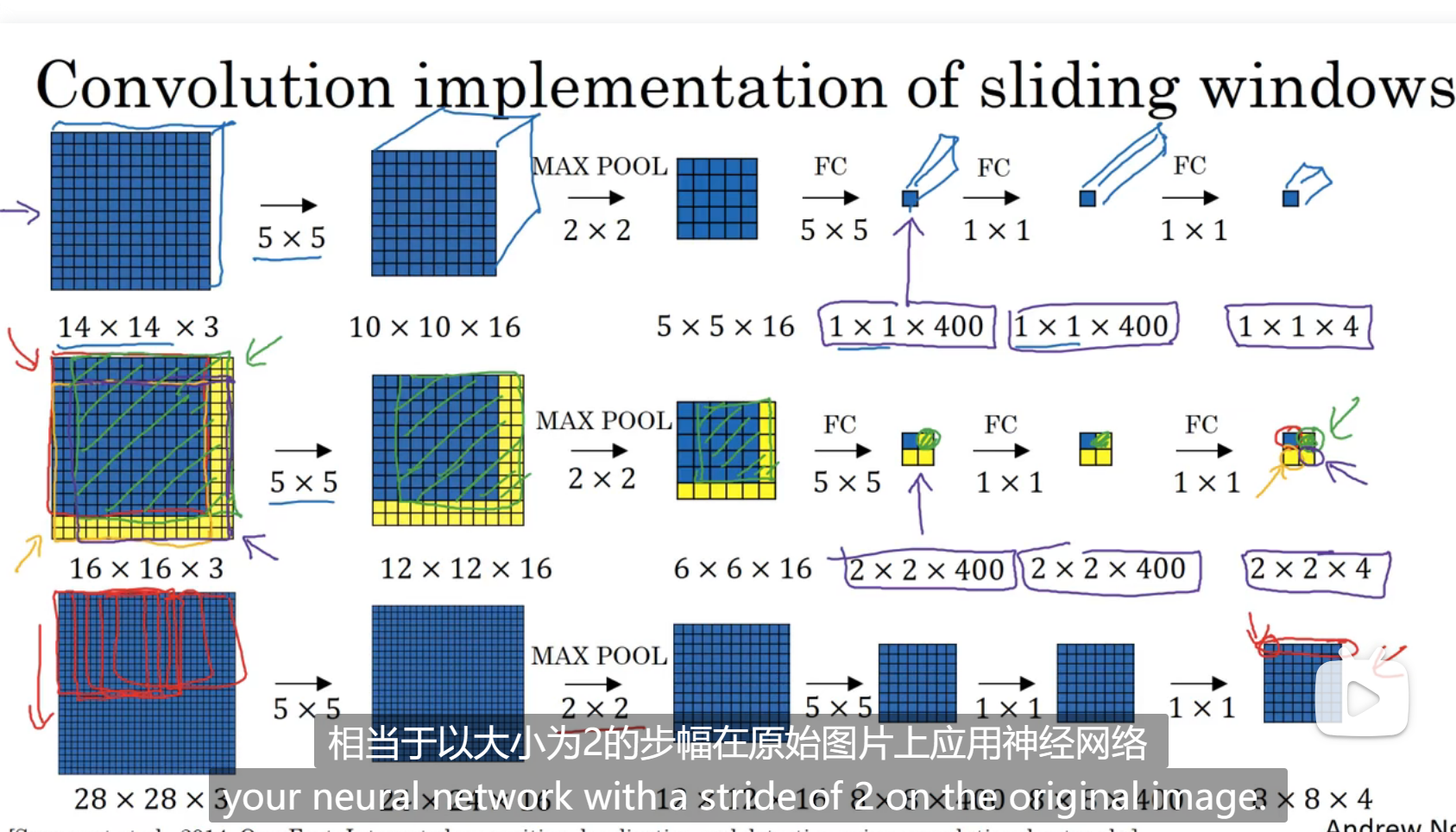
我们不用将图片划分成多个样本,直接在一张图片上做预测,最后的结果是一点,当然不止一点,一点以及它后面的所有信道
Bounding Box预测
上节不能输出精确的边界框,能识别在某一个框中有对象,但是不一定正好包括
Yolo算法(比如下图,将输入分成3 * 3的格子,最后的输出也是3 * 3的,然后每个格子的输出包括了其是否有对象,有对象的话对象的中点坐标,长和宽):
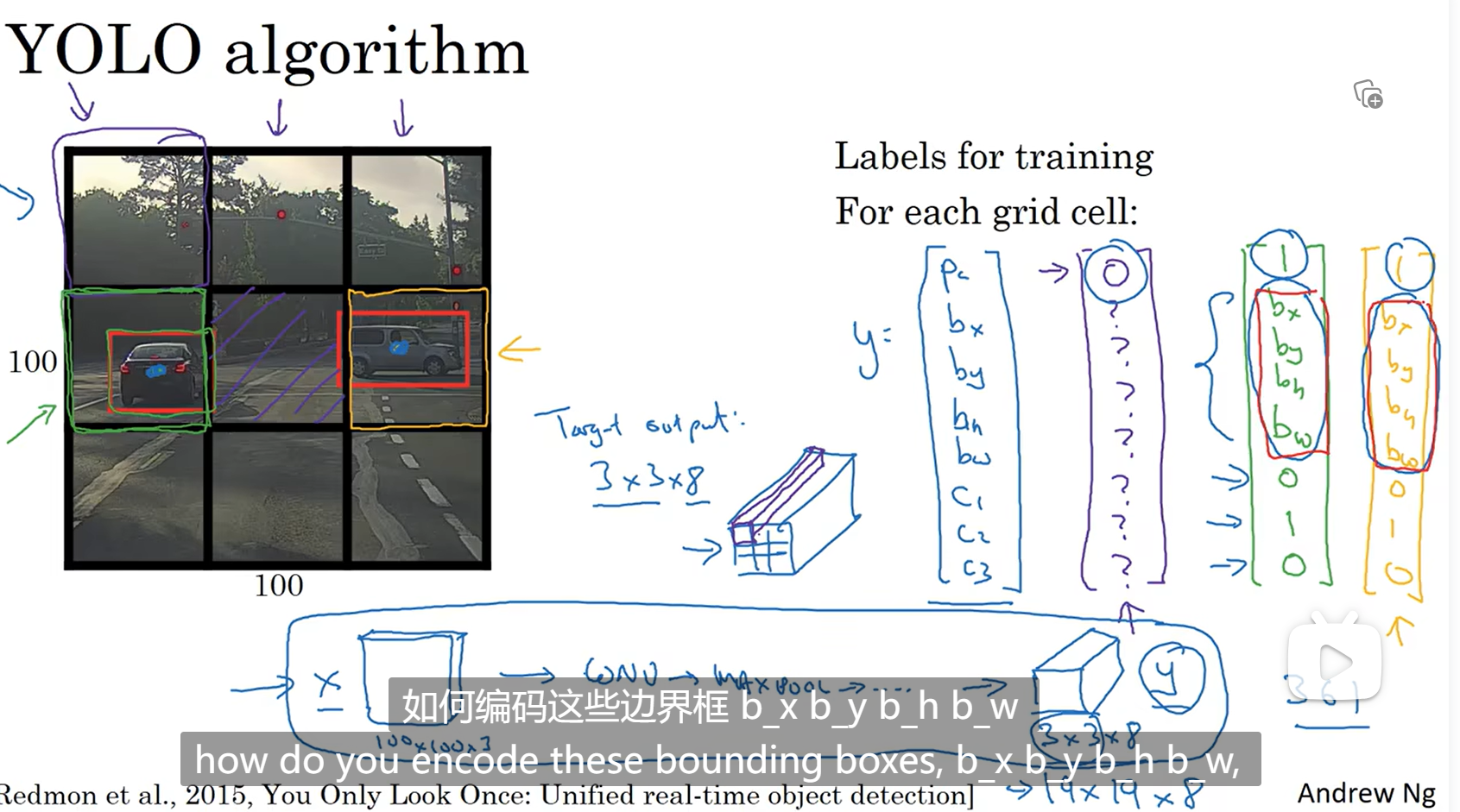
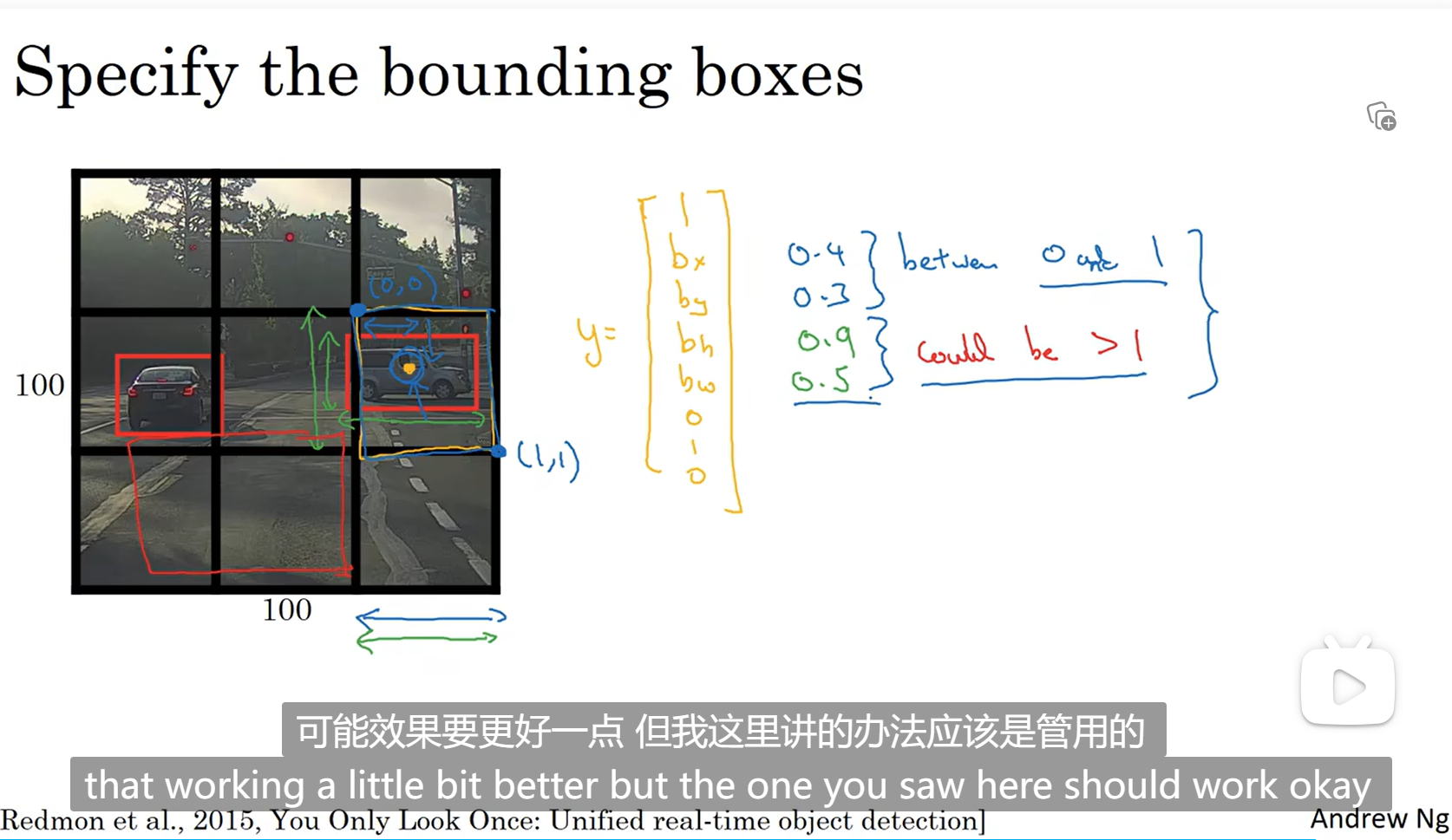
中点在该格子中才代表该格子有对象,但是长和宽不一定在格子里面,这里是前面所说的一个格子的坐标在(0,0)-(1,1)之间,所有说中点坐标在0-1之间
交并比
用于判断对象检测是否准确(loU代表检测出来的边框和实际的交集和并集的比值,通常这个比值大于等于0.5就认为准确):

非极大值抑制
当多个格子都认为自己包含了同一辆车子的中点,那就取pc值最大的那个中点

对象检测,识别出边框之后首先去掉pc值比较低的边框,针对同一个对象,选择最佳边框
对每个类别分别运行非最大值预测
Anchor Boxes
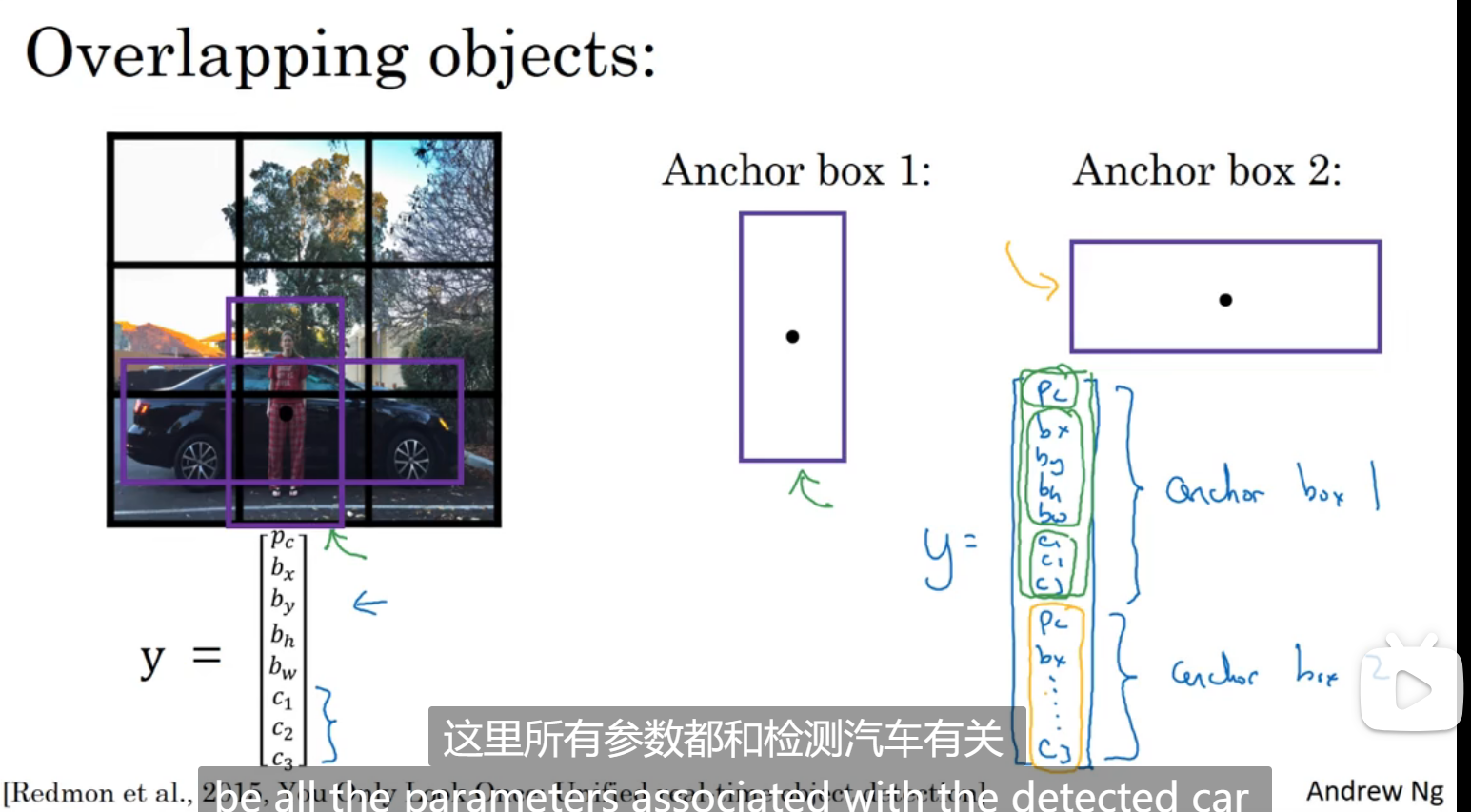
目前对象检测的局限有每个格子只能检测出一个对象
如图所示,y里面包含了两个pc,分别表示有车还是有人,或者是又有车又有人,如果想要有更多的对象,y的维度更高
Yolo算法

候选区域
R-CNN:带区域的卷积网络
将图像分成色块,因为如果整个图像都进行检测,很多窗口没有对象就会浪费性能,通过颜色分块,预测哪些块可能有对象

第二步:找到最大值的锚框的索引以及对应的最大值的锚框的分数
1 | 参数: |
box_classes是返回最大值的索引值,是(19,19,5,1),保留的是box_scores中每一个信道,在本题中就是80个里面最大值的索引值
box_class_scores是返回80个中的最大值
深度学习week4_3
install_url to use ShareThis. Please set it in _config.yml.


