week2_3
版权申明:本文为原创文章,转载请注明原文出处
week2_3
调试处理
超参数:α β β1 β2 layers ε hidden-units learning-rate decay mini-batch-size
红色是最需要调试的,其次是黄色,再其次是紫色 β是指用momentum是的参数 β1、β2是指用adam所有的参数
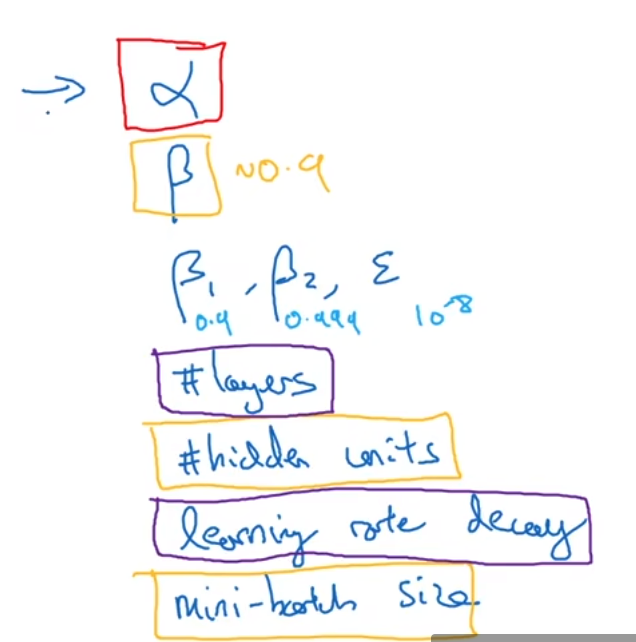
两个超参数选择
方法一:传统方法,取取样点,比如下图可以尝试这二十五个点,然后选择哪个参数最好,当参数的数量相对较小时,实用
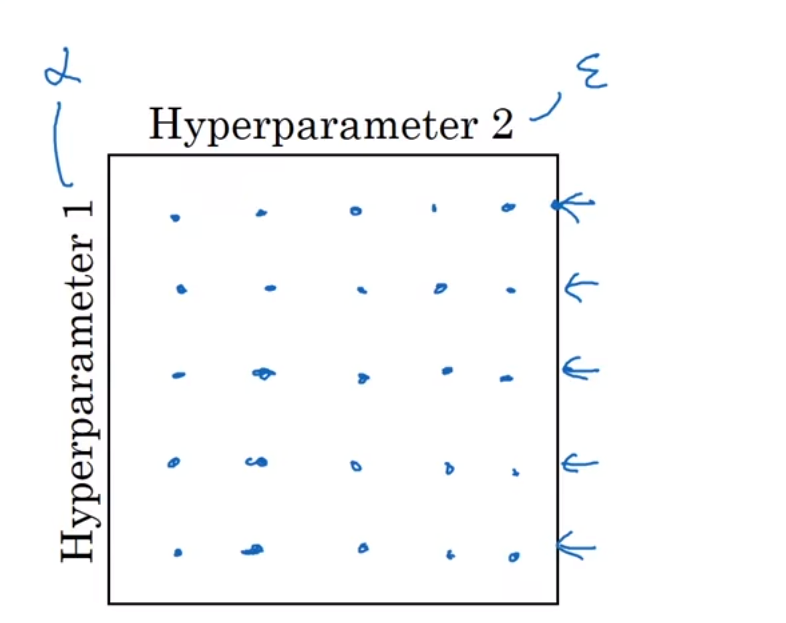
方法二:随机选择取样点,因为可能这两个超参数影响度不一样,可能有一个超参数不会起很大作用,那另一个如果用传统方法只有五个可选点,比较少
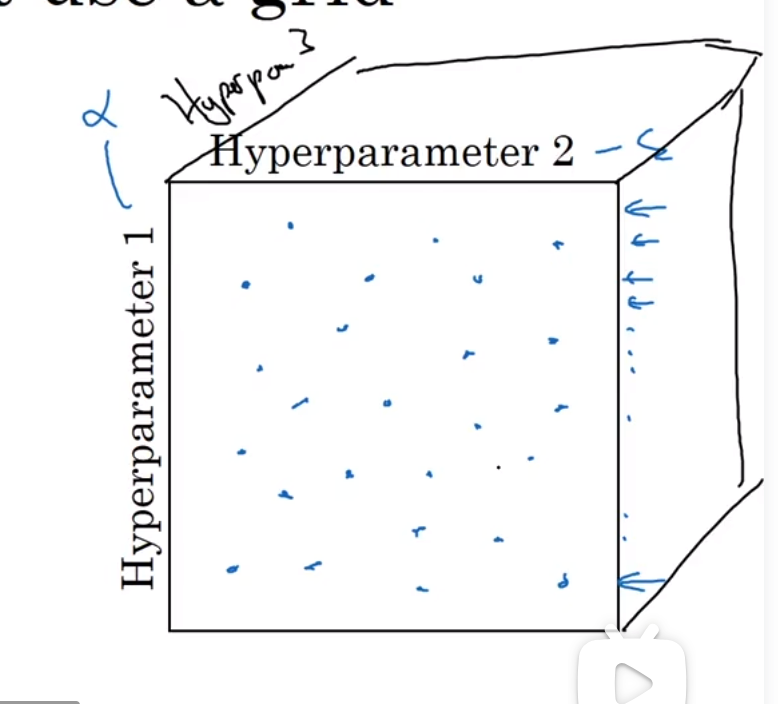
对于三层,再进行扩展
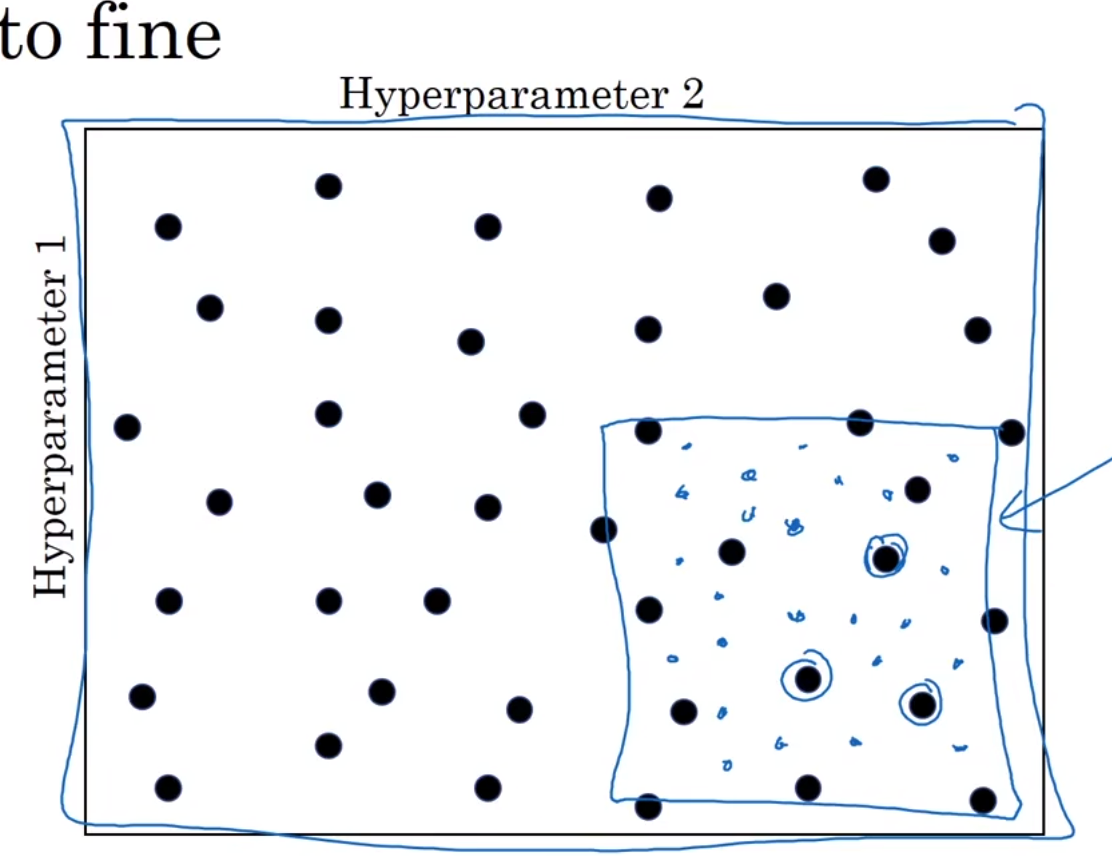
如果发现某一个区域的效果都比较好,那就放大这个区域,然后再精确的取一些值
为超参数选择合适的范围
随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的步进值
如果要选择α在0.0001-1,这样选择0.1-1之间的概率会比较高
所以更好的方法是设置每一组随机选择的概率相同

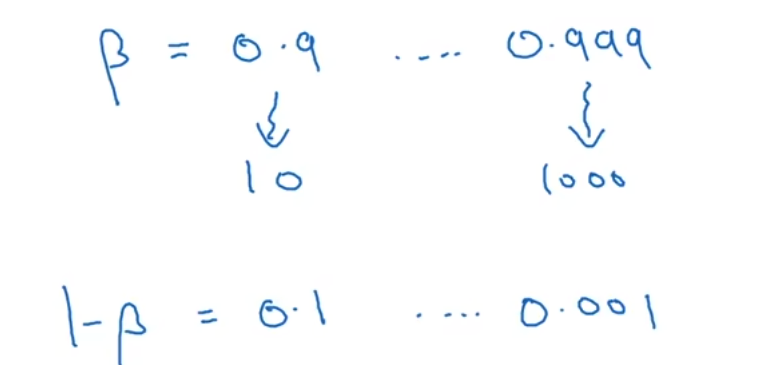
超参数训练的实践
Babysitting one model:每隔一个阶段就观察成本函数,并根据成本函数的变化趋势调整参数,这种方法通常是在计算机计算能力不够的时候进行的(panda,熊猫)
Training many models in parallel:多个模型同时运行,选择效果最好的(cavier,鱼子酱)
正则化网络的激活函数
batch归一化,这种方法可以使我的参数搜索问题变得简单,使神经网络对超参数的选择更加稳定,超参数的范围会庞大,工作效果也更好
在逻辑回归归一化设置中 X-=μ X/=σ
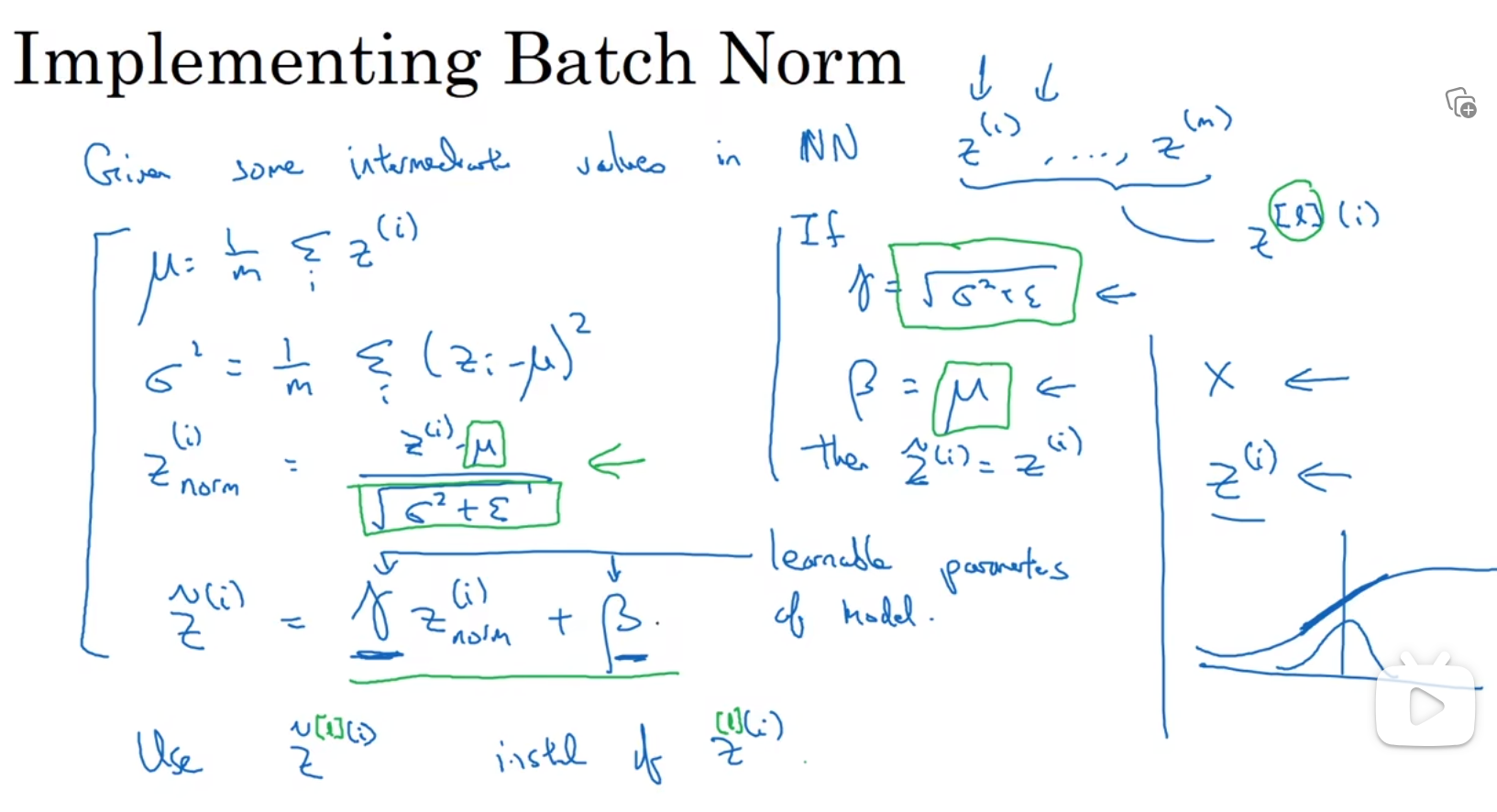
对于batch归一化,归一上一层的a[i],以更快速的训练W[3]b[3],实际上我们归一的是z[i]不是a[i]
可以选择直接归一化,和逻辑回归归一化一样,这样z会有平均值0和方差1,但是通常我们希望z有平均值和方差,γ和β可以仿造w和b权重更新的方法进行更新 γ和β是为了设置z的平均值和方差
将Batch Norm拟合进神经网络
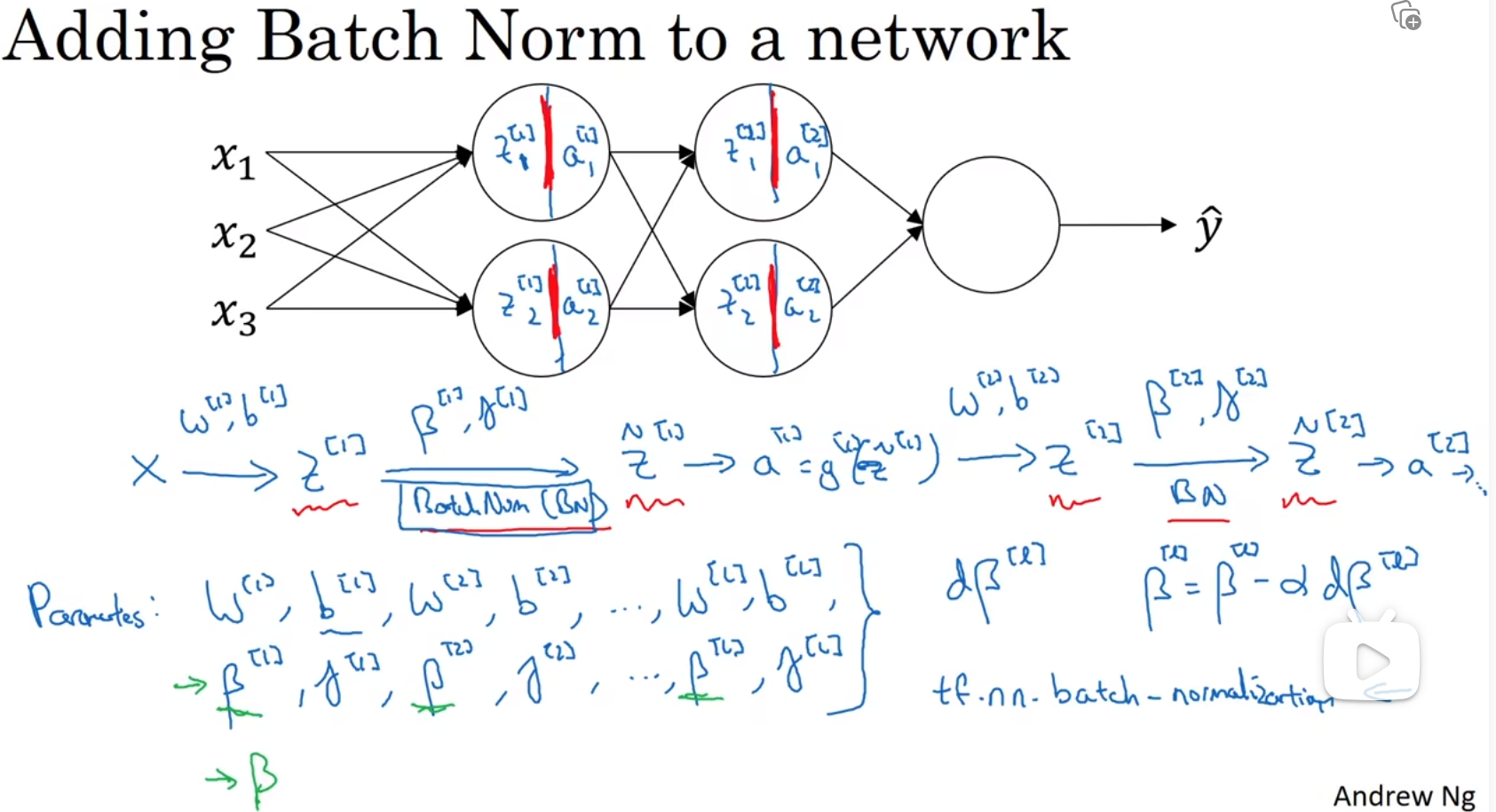
b[i]在这里作用不大,因为z进行batch归一化的时候,会先将均值设置为0,这样的话b[i]的用处就不大,可以去掉,注意β[i]和γ[i]的维度都是n[l] * 1

伪代码:
1 | for t in range(1,numMiniBatches): |
这里的parameters有参数 W β γ grads对应

Batch Norm为什么奏效
测试时的Batch Norm
μ和σ通常用指数加权平均来估算
到最后测试的时候,就不再计算μ和σ

Softmax回归
不再是只识别两个分类,可以识别多个分类
参数:C表示输入会被分入的类别总个数 最后一层的维数不再是1,而是4了(是4的原因是这儿有四个输出变量)
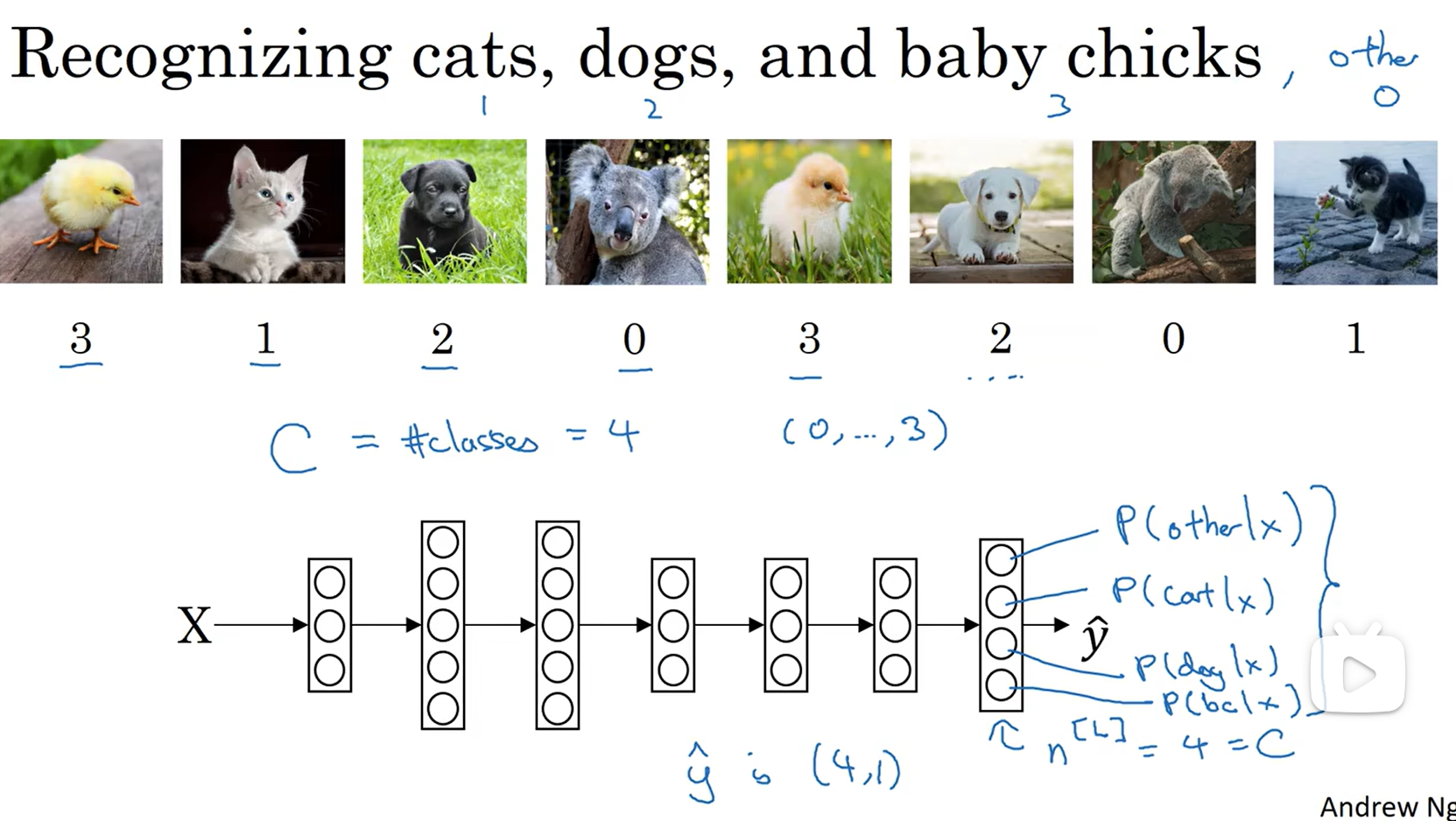
最后一层应用Softmax激活函数
参数:临时变量 t=e^z[l]
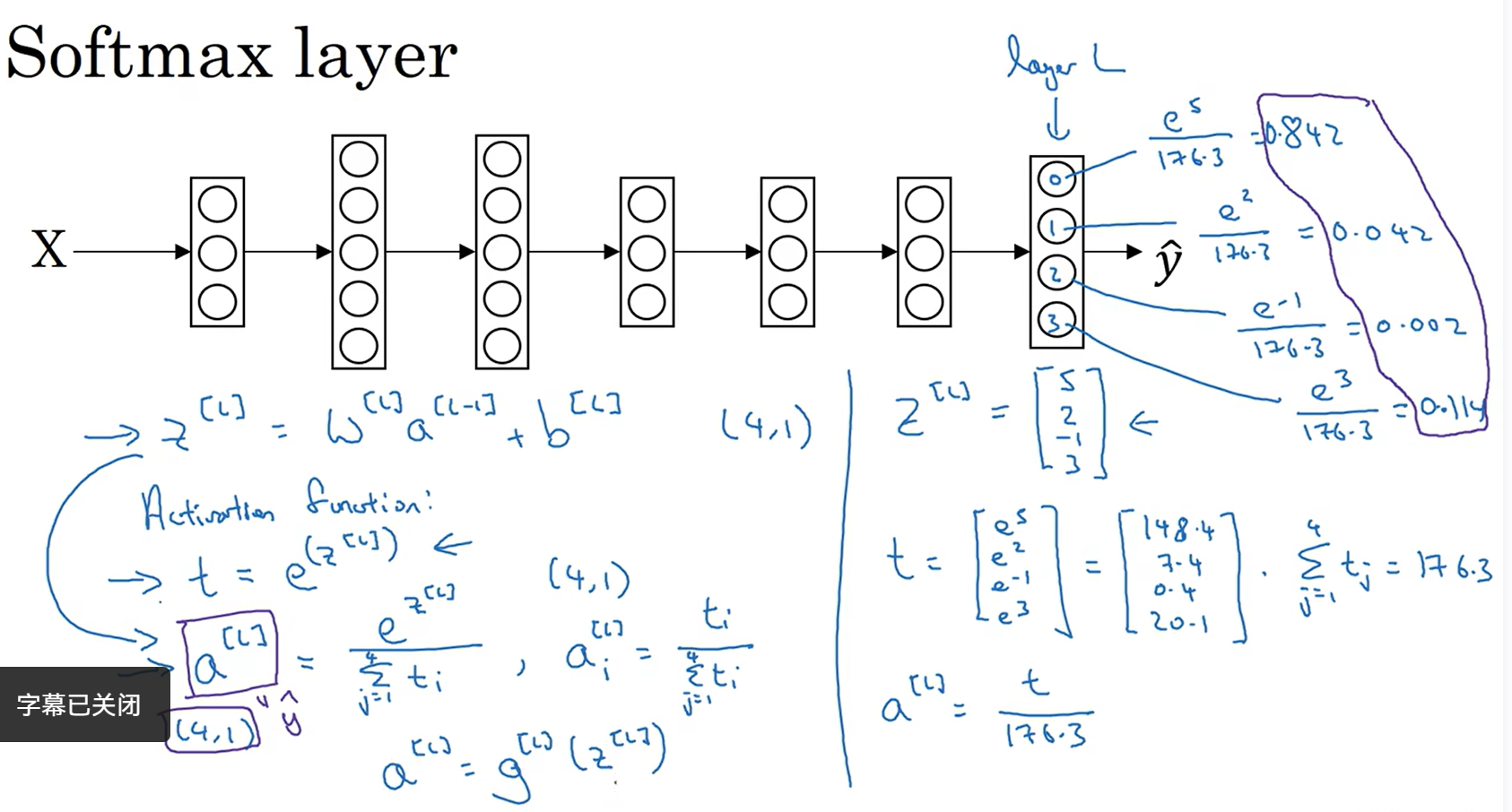
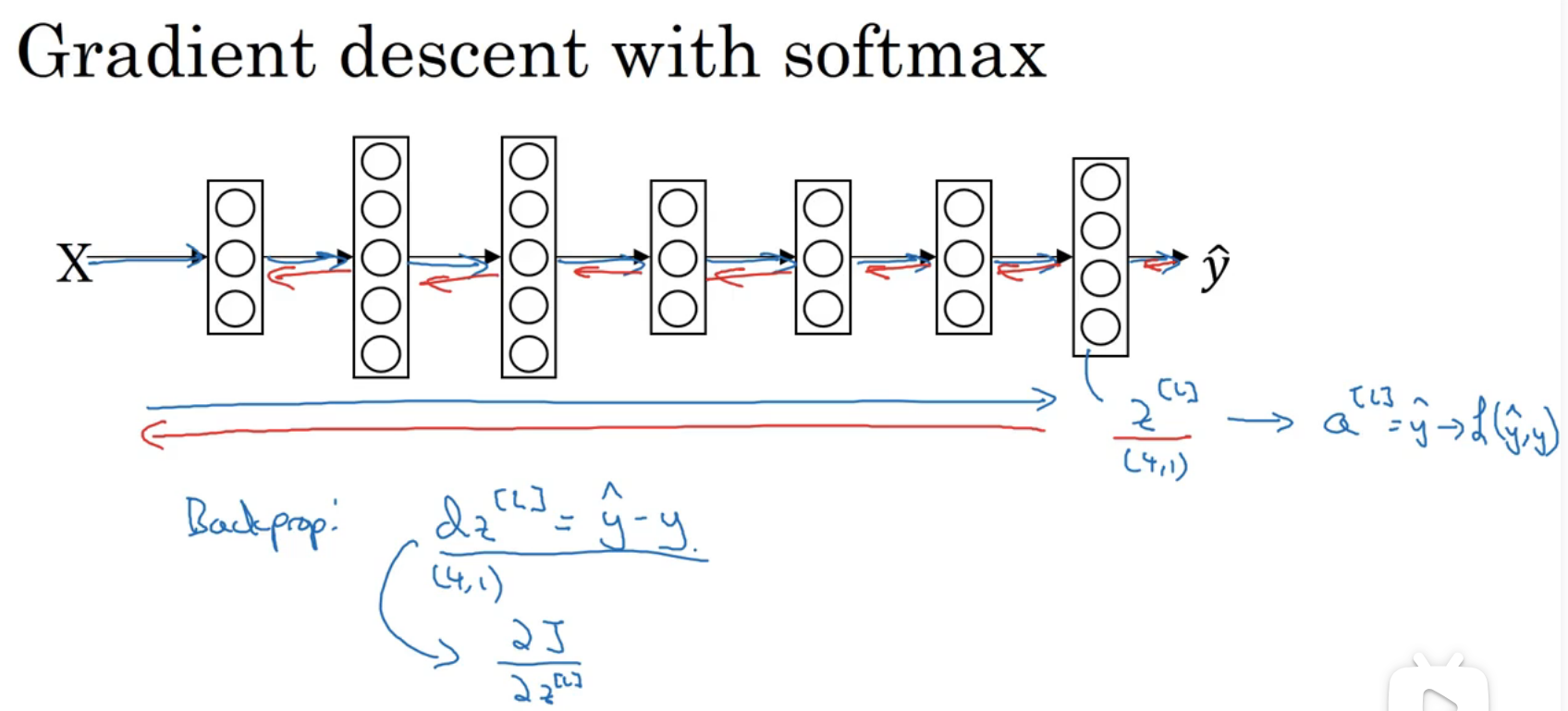
训练一个Softmax分类器
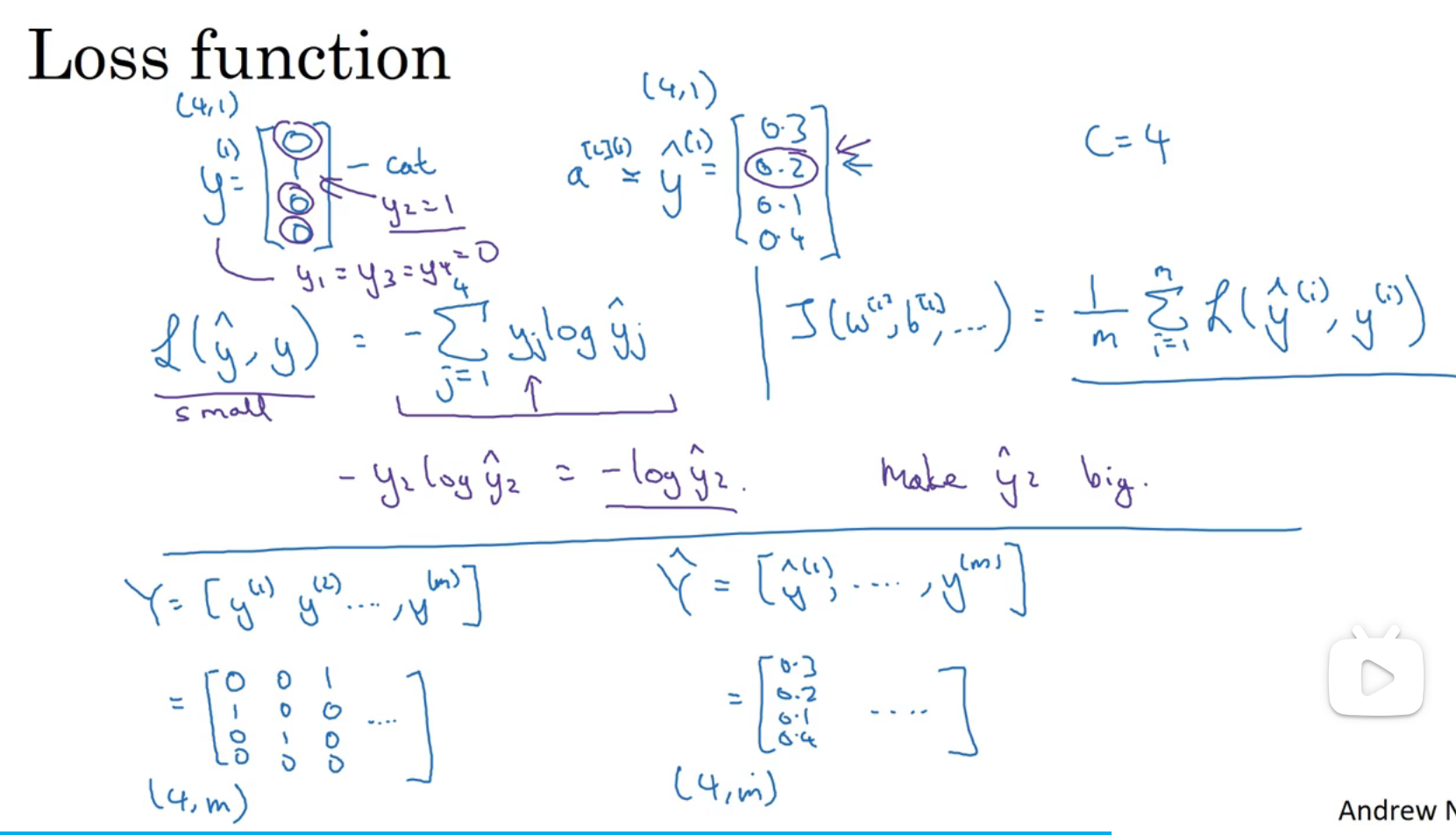
损失函数和成本函数的计算:
深度学习框架
eg:

TensorFlow
一种深度学习框架 只需要我们写正向传播,会自动帮我们计算反向传播
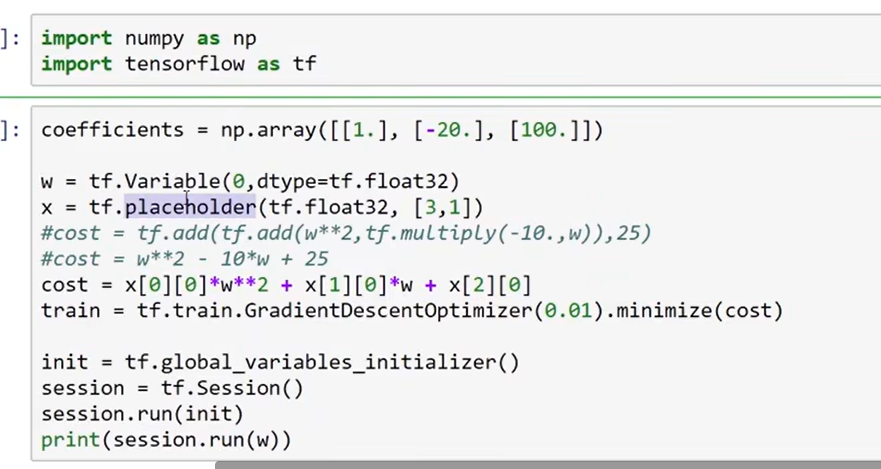
placeholder在这儿表示等会就会提供x的值,提供方式如下:
session相同表示方法:

对于Tensorflow的代码实现而言,实现代码的结构如下:
- 创建Tensorflow变量(此时,尚未直接计算)
- 实现Tensorflow变量之间的操作定义
- 初始化Tensorflow变量
- 创建Session
- 运行Session,此时,之前编写操作都会在这一步运行。
测试题
1.If your Neural Network model seems to have high variance, what of the following would be promising things to try? (如果你的神经网络模型似乎有很高的方差,下列哪个尝试是可能解决问题的?)
【★】Add regularization(添加正则化)
【★】Get more training data (获取更多的训练数据)
2.Which of these techniques are useful for reducing variance (reducing overfitting)? (Check all that apply.) (以下哪些技术可用于减少方差(减少过拟合))
【★】Dropout
【★】L2 regularization (L2 正则化)
【★】Data augmentation(数据增强)
3.Which of these statements about mini-batch gradient descent do you agree with?(关于 minibatch 的说法哪个是正确的?)
【 】You should implement mini-batch gradient descent without an explicit for-loop over different mini-batches, so that the algorithm processes all mini-batches at the same time (vectorization).(在不同的 mini-batch 下,不需要显式地进行循环,就可以实现 mini-batch 梯度下降,从而使算法同时处理所有的数据(向量化))
【 】 Training one epoch (one pass through the training set) using mini-batch gradient descent is faster than training one epoch using batch gradient descent.(使用 mini-batch 梯度下降训练的时间(一次训练完整个训练集)比使用梯度下降训练的时间要快。)
【★】One iteration of mini-batch gradient descent (computing on a single mini-batch) is faster than one iteration of batch gradient descent.(mini-batch 梯度下降(在单个 mini-batch 上计算)的一次迭代快于梯度下降的迭代。)
4.During hyperparameter search, whether you try to babysit one model (“Panda” strategy) or train a lot of models in parallel (“Caviar”) is largely determined by: (在超参数搜索过程中,你尝试只照顾一个模型(使用熊猫策略)还是一起训练大量的模型(鱼子酱策略)在很大程度上取决于:)
【 】Whether you use batch or mini-batch optimization (是否使用批量(batch)或小批量优化(mini-batch optimization))
【 】The presence of local minima (and saddle points) in your neural network (神经网络中局部最小值(鞍点)的存在性)
【★】The amount of computational power you can access (在你能力范围内,你能够拥有多大的计算能力)
【 】 The number of hyperparameters you have to tune(需要调整的超参数的数量)
5.Which of the following statements about γ and β in Batch Norm are true? Only correct options listed(Batch Norm 中关于 γ 和 β 的以下哪些陈述是正确的?)
【★】They can be learned using Adam, Gradient descent with momentum, or RMSprop, not just with gradient descent. (它们可以在 Adam、具有动量的梯度下降或 RMSprop 使中用,而不仅仅是用梯度下降来学习。)
【★】They set the mean and variance of the linear variable 𝑧 [𝑙] of a given layer.( 它们设定给定层的线性变量𝑧 [𝑙] 的均值和方差)
install_url to use ShareThis. Please set it in _config.yml.


