深度学习week5_3
基础模型
翻译模型(seq2seq):
- 建立一个编码网络,对输入进行编码,也就是进行学习
- 建立一个解码网络,当所有的输入完了之后对编码后的变量进行解码得到翻译的结果
翻译模型(seq2seq):
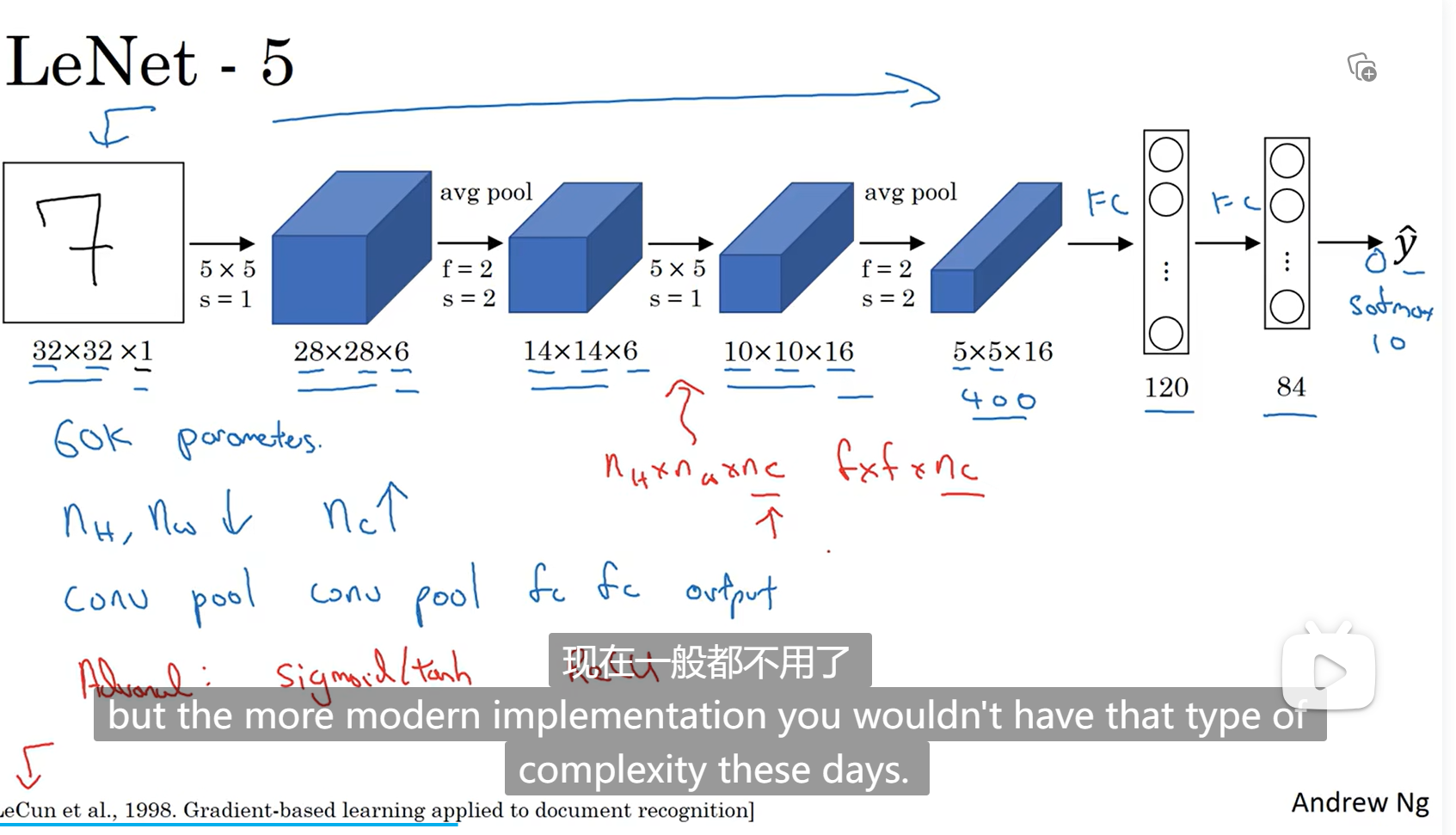
将RNN GRU LSTM用于自然语言处理(NLP)
词嵌入:让算法自动的理解一些类似的词
我们上周的理解是这样的,(one-hot)将所有词都存在一个词表里面,但是这样就会导致词和词之间是独立的,比如如下图的情况,orange和apple本来是很相近的两个词,比如下面两个句子都应该学习到后面的一个词是果汁,因为苹果和橙子是相近的两个词,但是如果相互独立就很难这么学习到:
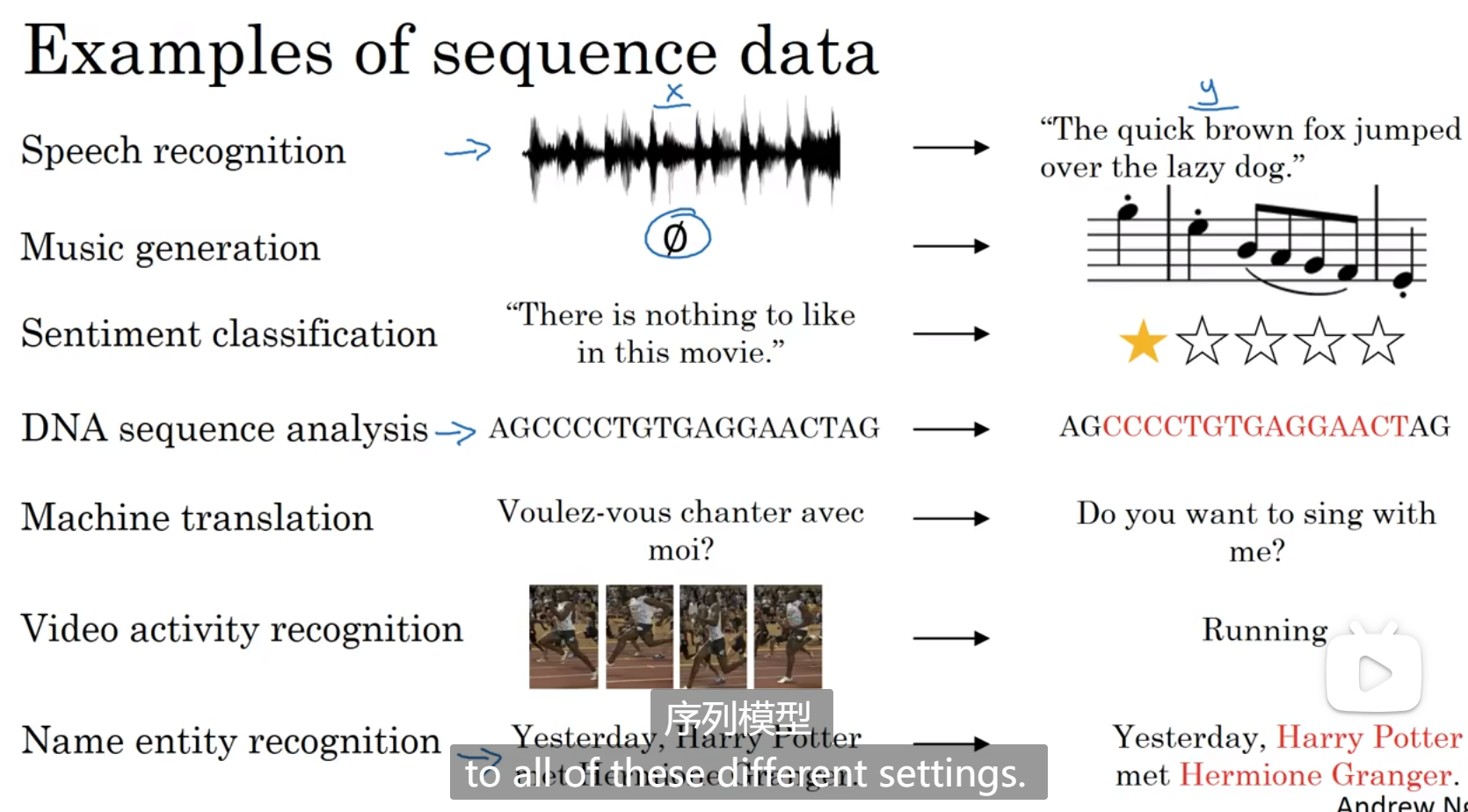
序列模型的适用范围
识别加验证
一次学习问题:需要通过单单一张照片去识别一个人
因为通常一个人只会录入它的一张照片,这对于神经网络来说样本数太少,除此之外,如果添加了新的人,就得重新训练模型
一种计算方法——计算相似度(这里的阈值时超参数,并且如果样本新增了一张图片也不会有问题,不需要重新训练,一张一张的比较):
对象位置分类(classification with localization):在一张图中有一个较大的对象,对他进行识别并确认出位置
对象检测(detection):在一张图中有多个对象,对这多个位置对象进行检测识别并确认出位置
在输出中添加位置标签,bx by是物体中心点的坐标,宽bw,高bh,整张图片起始坐标为(0,0),终坐标为(1,1)
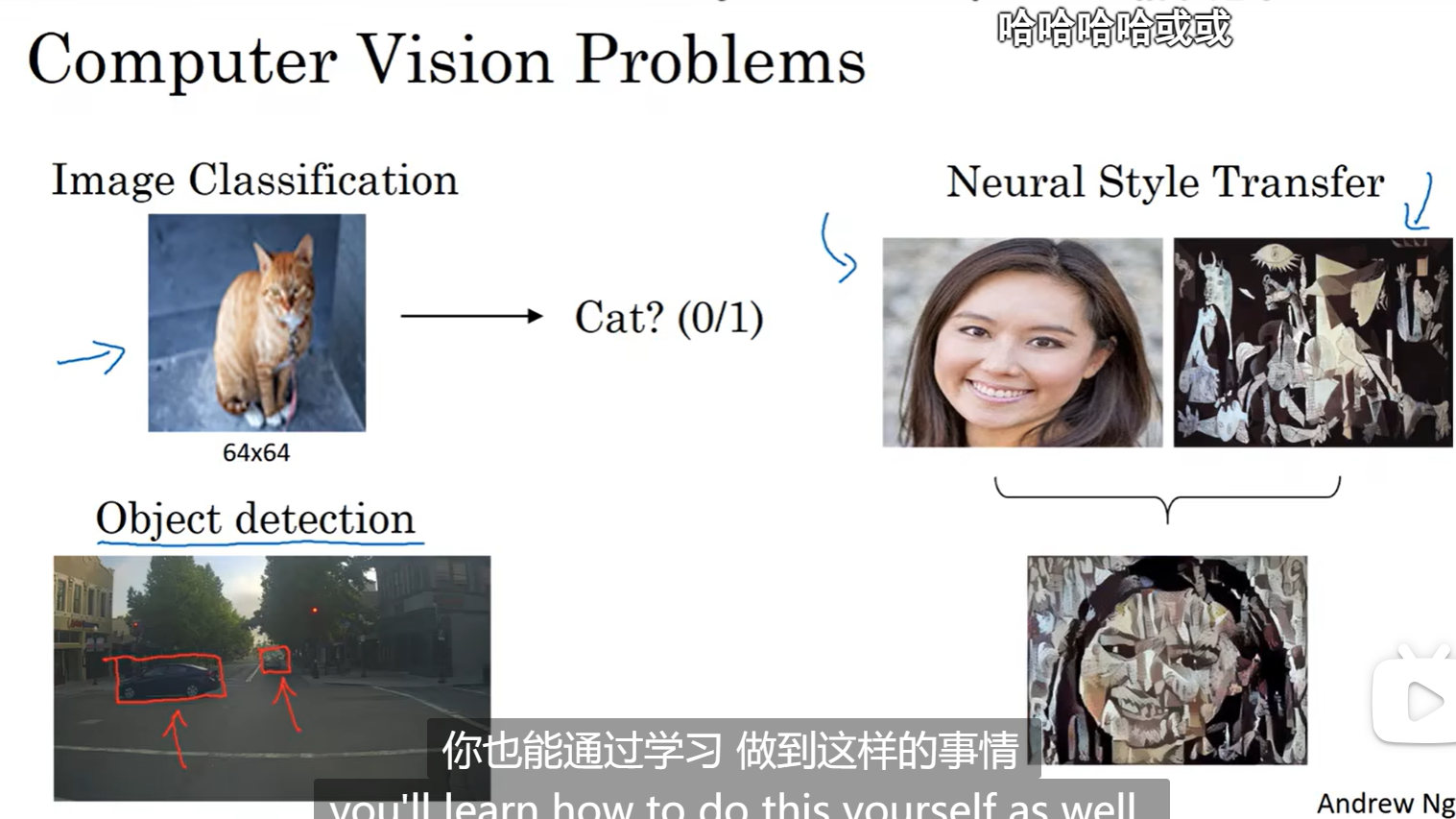
计算机视觉可以做到的事情(分类、识别、转换):